Cerebras Unveils Wafer Scale Engine Two (WSE2): 2.6 Trillion Transistors, 100% Yield
by Dr. Ian Cutress on April 20, 2021 2:00 PM EST
The last few years has seen a glut of processors enter the market with the sole purpose of accelerating artificial intelligence and machine learning workloads. Due to the different types of machine learning algorithms possible, these processors are often focused on a few key areas, but one thing limits them all – how big you can make the processor. Two years ago Cerebras unveiled a revolution in silicon design: a processor as big as your head, using as much area on a 12-inch wafer as a rectangular design would allow, built on 16nm, focused on both AI as well as HPC workloads. Today the company is launching its second generation product, built on TSMC 7nm, with more than double the cores and more than double of everything.
Second Generation Wafer Scale Engine
The new processor from Cerebras builds on the first by moving to TSMC’s N7 process. This allows the logic to scale down, as well as to some extent the SRAMs, and now the new chip has 850,000 AI cores on board. Basically almost everything about the new chip is over 2x:
| Cerebras Wafer Scale | |||
| AnandTech | Wafer Scale Engine Gen1 |
Wafer Scale Engine Gen2 |
Increase |
| AI Cores | 400,000 | 850,000 | 2.13x |
| Manufacturing | TSMC 16nm | TSMC 7nm | - |
| Launch Date | August 2019 | Q3 2021 | - |
| Die Size | 46225 mm2 | 46225 mm2 | - |
| Transistors | 1200 billion | 2600 billion | 2.17x |
| (Density) | 25.96 mTr/mm2 | 56.246 mTr/mm2 | 2.17x |
| On-board SRAM | 18 GB | 40 GB | 2.22x |
| Memory Bandwidth | 9 PB/s | 20 PB/s | 2.22x |
| Fabric Bandwidth | 100 Pb/s | 220 Pb/s | 2.22x |
| Cost | $2 million+ | arm+leg | ‽ |
As with the original processor, known as the Wafer Scale Engine (WSE-1), the new WSE-2 features hundreds of thousands of AI cores across a massive 46225 mm2 of silicon. In that space, Cerebras has enabled 2.6 trillion transistors for 850,000 cores - by comparison, the second biggest AI CPU on the market is ~826 mm2, with 0.054 trillion transistors. Cerebras also cites 1000x more onboard memory, with 40 GB of SRAM, compared to 40 MB on the Ampere A100.

Me with Wafer Scale Gen1 - looks the same, but with less than half the cores.
The cores are connected with a 2D Mesh with FMAC datapaths. Cerebras achieves 100% yield by designing a system in which any manufacturing defect can be bypassed – initially Cerebras had 1.5% extra cores to allow for defects, but we’ve since been told this was way too much as TSMC's process is so mature. Cerebras’ goal with WSE is to provide a single platform, designed through innovative patents, that allowed for bigger processors useful in AI calculations but has also been extended into a wider array of HPC workloads.
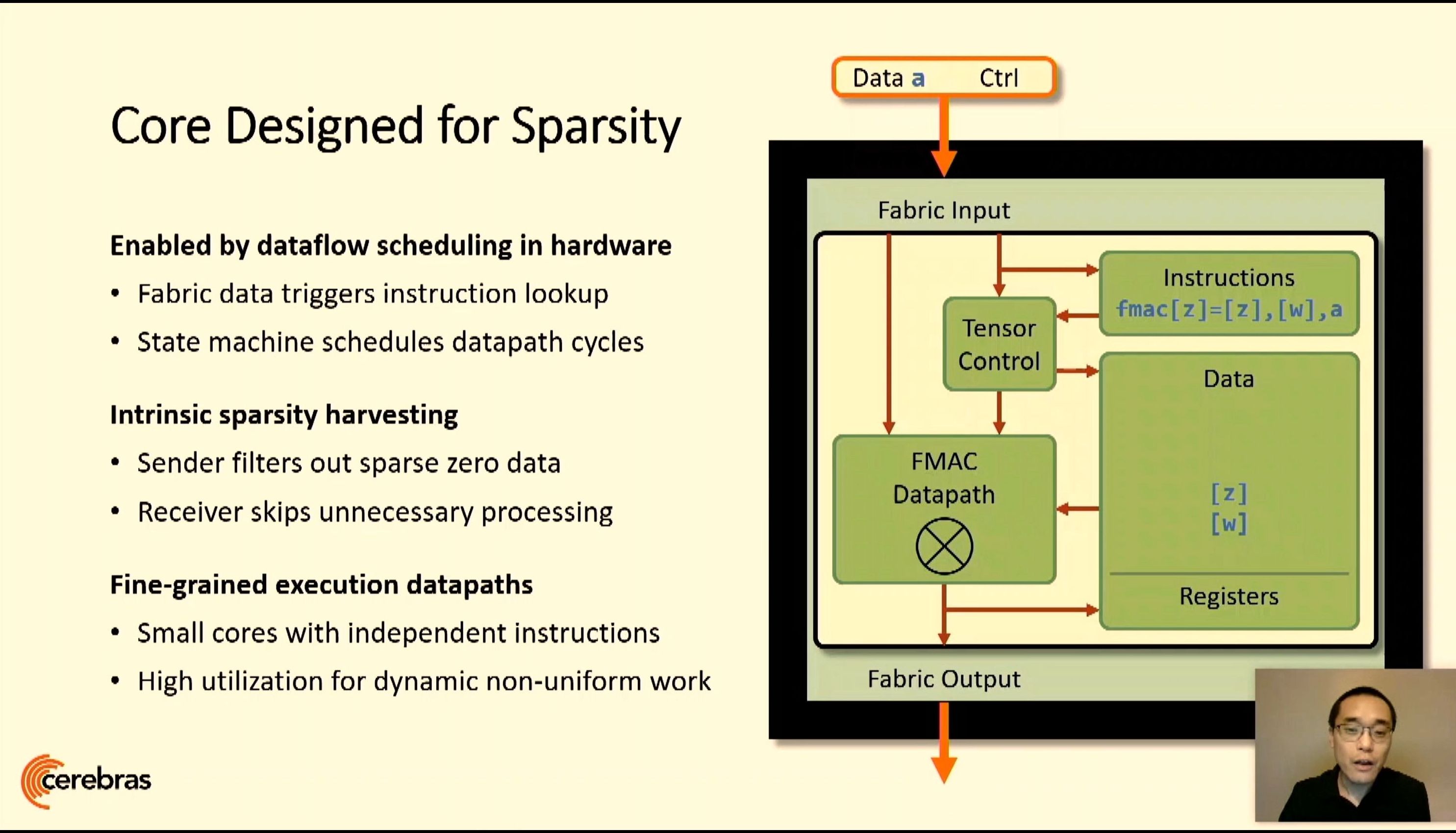
Building on First Gen WSE
A key to the design is the custom graph compiler, that takes pyTorch or TensorFlow and maps each layer to a physical part of the chip, allowing for asynchronous compute as the data flows through. Having such a large processor means the data never has to go off-die and wait in memory, wasting power, and can continually be moved onto the next stage of the calculation in a pipelined fashion. The compiler and processor are also designed with sparsity in mind, allowing high utilization regardless of batch size, or can enable parameter search algorithms to run simultaneously.

For Cerebras’ first generation WSE is sold as a complete system called CS-1, and the company has several dozen customers with deployed systems up and running, including a number of research laboratories, pharmaceutical companies, biotechnology research, military, and the oil and gas industries. Lawrence Livermore has a CS-1 paired to its 23 PFLOP ‘Lassen’ Supercomputer. Pittsburgh Supercomputer Center purchased two systems with a $5m grant, and these systems are attached to their Neocortex supercomputer, allowing for simultaneous AI and enhanced compute.
Products and Partnerships
Cerebras sells complete CS-1 systems today as a 15U box that contains one WSE-1 along with 12x100 GbE, twelve 4 kW power supplies (6 redundant, peak power about 23 kW), and deployments at some institutions are paired with HPE’s SuperDome Flex. The new CS-2 system shares this same configuration, albeit with more than double the cores and double the on-board memory, but still within the same power. Compared to other platforms, these processors are arranged vertically inside the 15U design in order to enable ease of access as well as built-in liquid cooling across such a large processor. It should also be noted that those front doors are machined from a single piece of aluminium.

The uniqueness of Cerebras’ design is being able to go beyond the physical manufacturing limits normally presented in manufacturing, known as the reticle limit. Processors are designed with this limit as the maximum size of a chip, as connecting two areas with a cross-reticle connection is difficult. This is part of the secret sauce that Cerebras brings to the table, and the company remains the only one offering a processor on this scale – the same patents that Cerebras developed and were awarded to build these large chips are still in play here, and the second gen WSE will be built into CS-2 systems with a similar design to CS-1 in terms of connectivity and visuals.

The same compiler and software packages with updates enable any customer that has been trialling AI workloads with the first system to use the second at the point at which they deploy one. Cerebras has been working on higher-level implementations to enable customers with standardized TensorFlow and PyTorch models very quick assimilation of their existing GPU code by adding three lines of code and using Cerebras’ graph compiler. The compiler then divides the whole 850,000 cores into segments of each layer that allow for data flow in a pipelined fashion without stalls. The silicon can also be used for multiple networks simultaneously for parameter search.

Cerebras states that with having such a large single chip solution means that the barrier to distributed training methods across 100s of AI chips is now so much further away that this excess complication is not needed in most scenarios – to that, we’re seeing CS-1 deployments of single systems attached to supercomputers. However, Cerebras is keen to point out that two CS-2 systems will deliver 1.7 million AI cores in a standard 42U rack, or three systems for 2.55 million in a larger 46U rack (assuming there’s sufficient power for all at once!), replacing a dozen racks of alternative compute hardware. At Hot Chips 2020, Chief Hardware Architect Sean Lie stated that one of Cerebras' key benefits to customers was the ability to enable workload simplification that previously required racks of GPU/TPU but instead can run on a single WSE in a computationally relevant fashion.

As a company, Cerebras has ~300 staff across Toronto, San Diego, Tokyo, and San Francisco. They have dozens of customers already with CS-1 deployed and a number more already trialling CS-2 remotely as they bring up the commercial systems. Beyond AI, Cerebras is getting a lot of interest from typical commercial high performance compute markets, such as oil-and-gas and genomics, due to the flexibility of the chip is enabling fluid dynamics and other compute simulations. Deployments of CS-2 will occur later this year in Q3, and the price has risen from ~$2-3 million to ‘several’ million.

With Godzilla for a size reference
Related Reading
- Cerebras Wafer Scale Engine News: DoE Supercomputer Gets 400,000 AI Cores
- 342 Transistors for Every Person In the World: Cerebras 2nd Gen Wafer Scale Engine Teased
- Cerebras’ Wafer Scale Engine Scores a Sale: $5m Buys Two for PSC
- Hot Chips 2020 Live Blog: Cerebras WSE Programming (3:00pm PT)
- Hot Chips 2019 Live Blog: Cerebras' 1.2 Trillion Transistor Deep Learning Processor








136 Comments
View All Comments
Santoval - Friday, April 23, 2021 - link
Because in that case the individual dies would also need to be round, and that would be impractical at best, impossible at worst. Dies have always been rectangular shaped for a very good reason. While squaring the circle is possible (with enough squares) circling the squares is not possible, at least in this case.Making the silicon wafers themselves square rather than round would be another idea, but it is also impractical due to the way silicon ingots are "grown" from "seeds" using crucibles.
flashmozzg - Tuesday, June 1, 2021 - link
https://www.youtube.com/watch?v=Rhs_NjaFxeoeastcoast_pete - Tuesday, April 20, 2021 - link
Thanks Ian! One thing that I am wondering about is whether TSMC is considered a "trusted foundry" by the US government? Isn't this device (calling it a chip is somewhat insulting) under significant export and sales restrictions? AFAIK, it can andis also used or can also be used for extremely high-throughput cryptography and analysis, and for simulations of, for example, new designs of nuclear warheads. That kind of tech is typically not freely sold, even if one can otherwise afford to pay the arms/legs pricetag.
alphasquadron - Tuesday, April 20, 2021 - link
Hi Eastcoast Pete, I can answer this. While they this could be used for dangerous reasons. Chips already exist out there that can perform cryptography. For example all the nvidia chips right now are sold out because people are using them for bitcoin mining which is kinda like cryptography. So to sum it up, it's really bullshit that I can't buy a nvidia card right now.mode_13h - Wednesday, April 21, 2021 - link
lolArbie - Tuesday, April 20, 2021 - link
But can it run Crysis?smalM - Tuesday, April 20, 2021 - link
No, but it can play Crysis...eastcoast_pete - Tuesday, April 20, 2021 - link
Yes, but why would it?Foeketijn - Wednesday, April 21, 2021 - link
That would be really interesting, seeing the best tactics being shaped. What if Camping is the best?What if it finds out how to overheat the GPU from other players? Seeing how inventive IA can be in playing digital hide and seek.
Linustechtips12#6900xt - Wednesday, April 21, 2021 - link
that way we could find the next crisis, that would honestly be really cool, like if you completed the first Crysis then there was like a mini Crysis 2 or a gameplay timeline u could play in that led up to Crysis 2 like a prologue or epilogue or whatever its called.