Supermicro Ultra SYS-120U-TNR Review: Testing Dual 10nm Ice Lake Xeon in 1U
by Dr. Ian Cutress on July 22, 2021 9:00 AM ESTSystem Results and Benchmarks
When it comes down to system tests, the most obvious case in point is power consumption. Running through our benchmark tests and the IPMI does a good job of monitoring the power consumption every few minutes. We managed to see a 747 Watt peak listed, however the graph to run a few quick last photos for this reviews is showing something north of 750W.
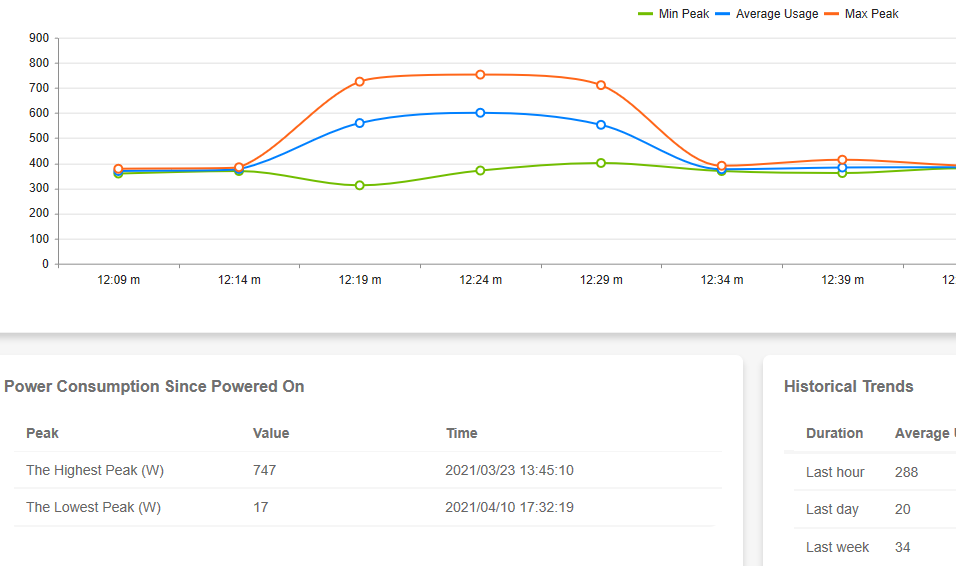
750W for a fully loaded dual 28C 2x205W system sounds quite high. This system has a peak of 1200W on the power supply, so that leaves 500W for an AI accelerator and anything additional. This means a good GPU and a dozen high power NVMe drives is about your limit. Luckily that's all you can fit into the system. Users who need 270 W processors in this system might have to cut back on some of the extras.
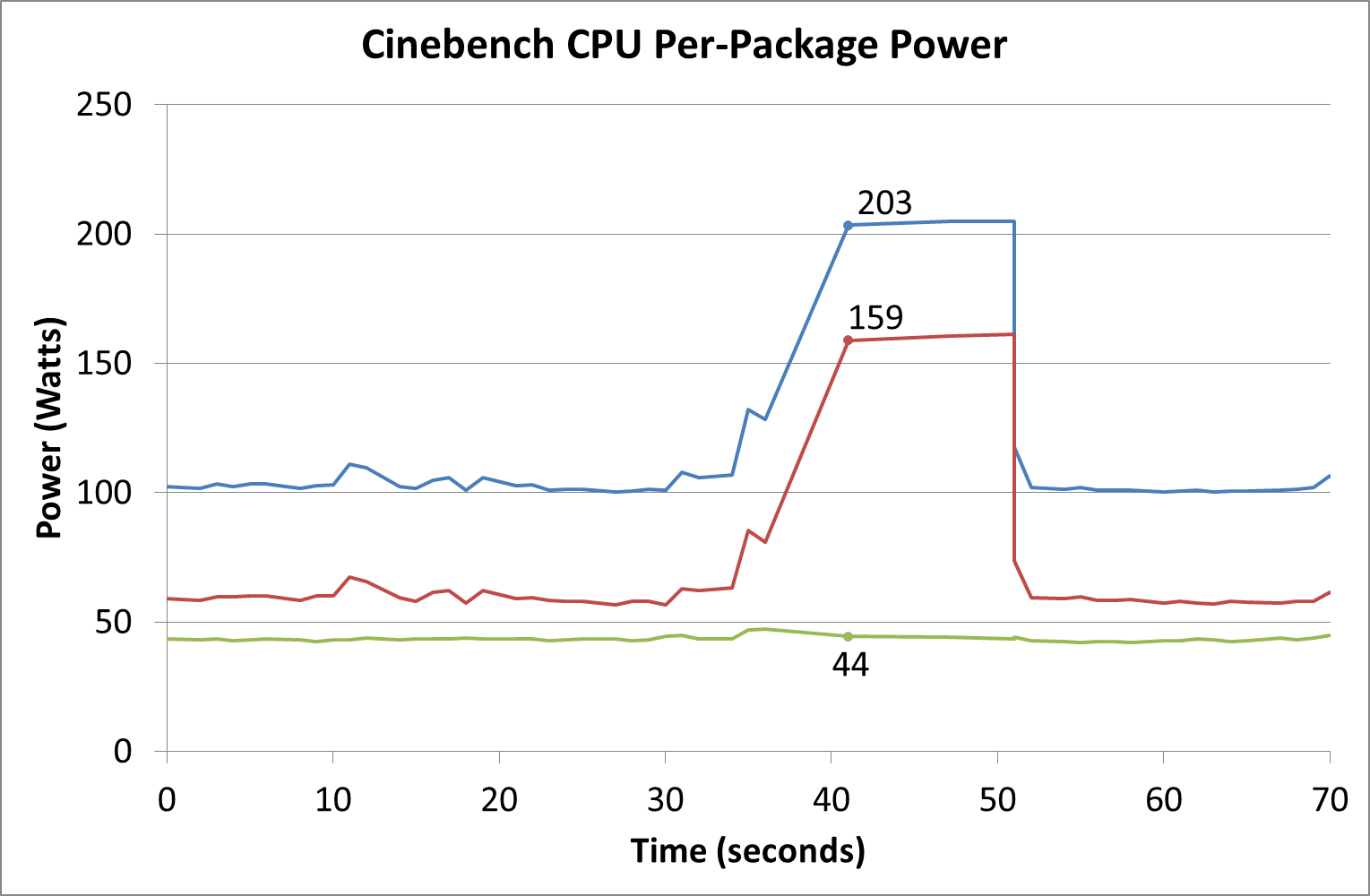
One of the elements in which to test this system at full power, and if we look at the processor power consumption we get about 205 W per processor (which is the rated TDP) during turbo.

Out of this power, it would appear that the idle power is around 100 W, which is split between cores/DRAM (we assume IO is under DRAM?). When loaded, extra budget goes into the processors. We see the same thing on CineBench, except there seems to be less stress on the DRAM/IO in this test.
Benchmarks
While we don't have a series of server specific tests, we are able to probe the capability of the system as delivered through mix of our enterprise and workstation testing. LLVM compile and SPEC are Linux based, while the rest are Windows, based on personal familiarity and also our back catalog of comparison data. It is worth noting that some software has difficulty scaling beyond 64 threads in Windows due to thread groups - this is down to the way the software is compiled and run. All the tests here were all able to dismiss this limitation except LinX LINPACK, which has a 64 thread limit (and is limited to Intel).
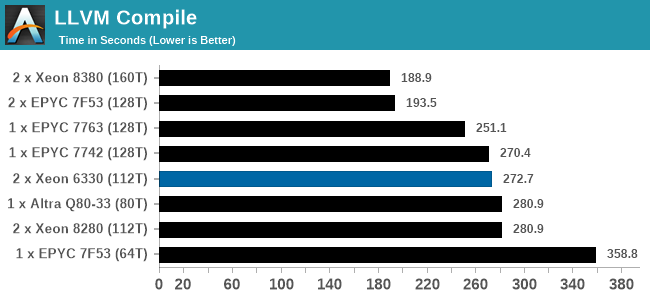
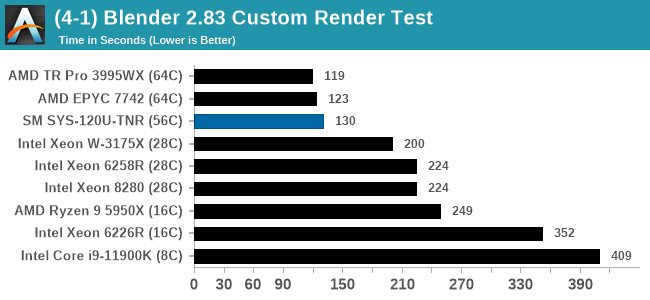
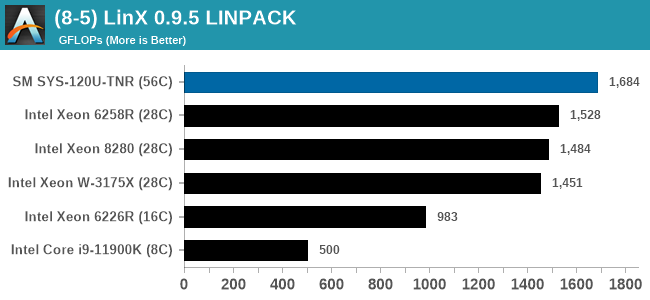
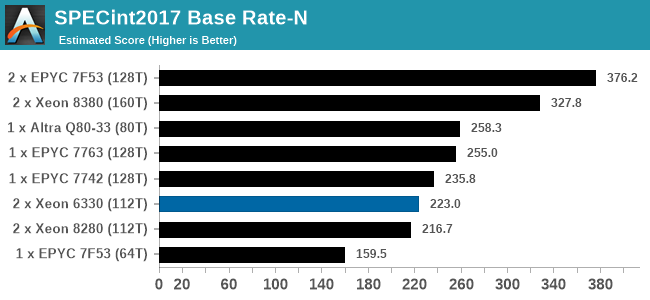
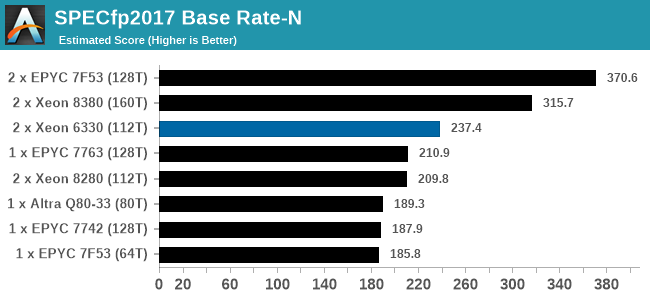
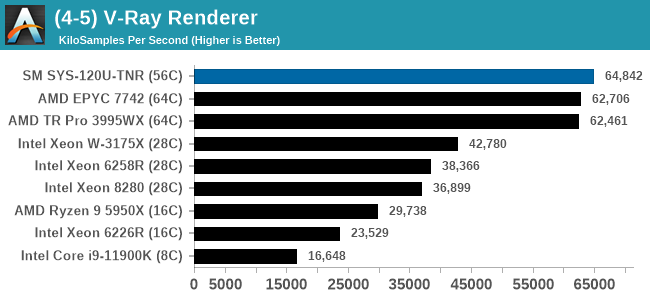
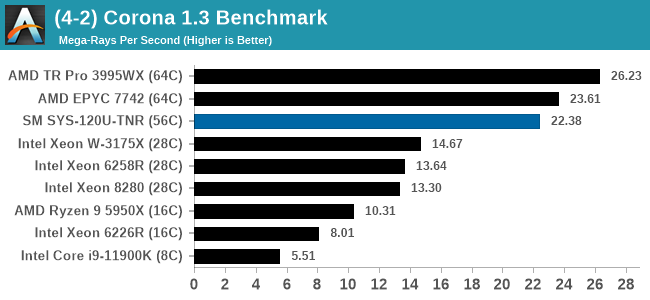
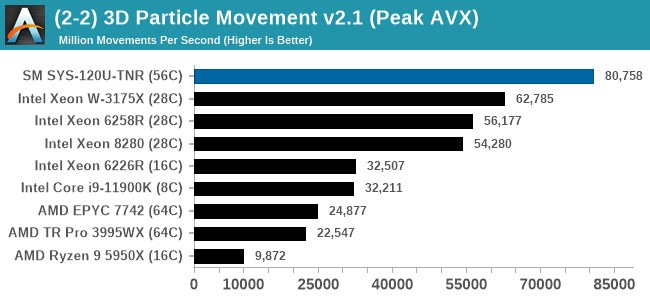
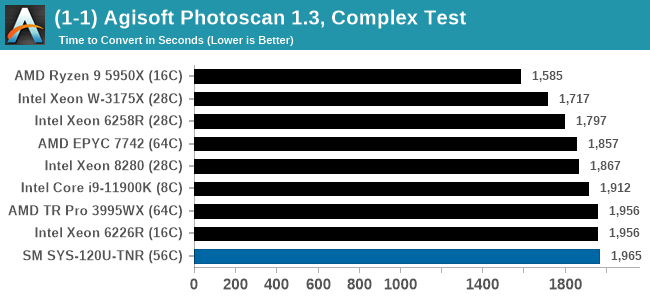
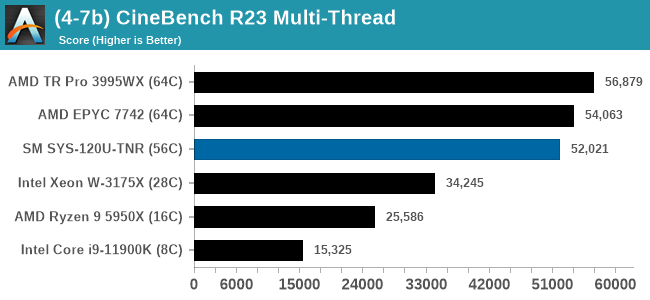
In almost all cases, the dual socket 28C SYS-120U-TNR sits behind the single socket 64C option from AMD. For the tests against dual 8280 or dual 6258R, we can see a generational uplift, however there is still a struggle against a AMD's previous generation top tier processor. That said, AMD's processor costs $6950, whereas two of these 6330s is around $3800. There is always a balance between price, total cost of ownership, and benefits versus the complexities of a dual socket system against a single socket system. The benchmarks where the SYS-120U-TNR did the best were our AVX tests, such as 3DPM and y-cruncher, where these processors could use AVX-512. As stated by Intel's Lisa Spelman in our recent interview, "70% of those deal wins, the reason listed by our salesforce for that win was AVX-512; optimization is real".








53 Comments
View All Comments
SSNSeawolf - Monday, July 26, 2021 - link
I'm curious why you say AMX is like AVX-8192. My understanding is that AMX is essentially a configurable fused multiply-add accelerator, with the added bonus of some configuration registers. However, I'm not an AI guy so I welcome corrections.mode_13h - Monday, July 26, 2021 - link
> I'm curious why you say AMX is like AVX-8192.Because that's how big the registers are. 1 kB each (there are 8 of them, BTW). As for the configurable part, it's true that operations don't have to use the entire register.
I'm not saying it *is* AVX-8192. Just that you could sort of look at it that way. The point was only to tie it into the lineage of what came before. For anything beyond that, you'll want to dig into the specifics and understand it for what it *is*.
mode_13h - Sunday, July 25, 2021 - link
If there's one thing Intel knows how to do, it's more of what they've done before!Foeketijn - Thursday, July 22, 2021 - link
Power and cooling is not cheap in a colo. Using 300W more for the same performance will set you back 1000 bucks a year easily.mode_13h - Thursday, July 22, 2021 - link
Yeah, I'd have expected power-efficiency to be the top priority, followed by density.Spunjji - Monday, July 26, 2021 - link
Ouch!mode_13h - Thursday, July 22, 2021 - link
Ian, the AVX 3DPM benchmark is concerning me. Given the grossly asymmetric optimization for AVX-512 vs. AVX2, I think it's not a good performance characterization for AVX2 vs. AVX-512 CPUs.If the AVX2 path could be optimized to a similar degree, then I think it would make sense to use it in that way. Unless/until that happens, I think you should only use it to compare like-for-like CPUs (i.e. AVX2 vs AVX2; AVX-512 vs AVX-512).
On a related note, please post the source somewhere like github, so that we actually see what it's measuring and potentially have a go at optimizing the AVX2 path, ourselves.
29a - Thursday, July 22, 2021 - link
I've also been complaining about ego mark forever and now they added that terrible AI benchmark to the lineup which they readily admit is bad data.mode_13h - Thursday, July 22, 2021 - link
He should just put it up on github and see what people can do with it. Plus, somebody might optimize it for ARM, too. He's already shared it with Intel and AMD, so what's the big deal?Dolda2000 - Thursday, July 22, 2021 - link
I don't think there's anything particularly wrong with that. It may be disproportionate to other benchmarks, but if all benchmarks scaled the same, there'd be no point in having more than one at all. It's a real-world workload (custom in-house programs are perhaps the most real-world workloads there are), and it does demonstrate the fact that some programs really benefit by AVX-512.Realistically, I don't think it should've been shared with Intel and AMD (it would've arguably been better if it were "pristine"), but given that that has been done, I'd agree there's no point to not making it public any longer. That being said, I'm not sure the point should be to microoptimize it to the ends of the world, or it wouldn't be a realistic workload any longer.