MIPS Announces I7200 32-bit CPU With New nanoMIPS ISA
by Andrei Frumusanu on May 1, 2018 10:00 AM ESTMIPS has been a common name in the computing industry for over 3 decades now, but it’s hard to argue against the fact that over the last few years the company has lost some of its luster as a result of increasingly strong competition from vendors such as Arm. While this has limited MIPS' success in the consumer-oriented products, it has been able to continue to stay extremely relevant in the networking space. Alongside that, it also has been able to carve itself a relevant niche in mobile communications processing, acting as the control processors for LTE modems inside SoCs.
Today’s announcement sees a new introduction of the mid-range 32-bit line of processors succeeding past interAptiv line-ups. The I7200 is a new processor targeting high performance embedded systems with real-time requirements.

The I-Class CPUs is the mid-range portfolio from MIPS. In the past we’ve covered the announcements of the I6400 in this line-up, as well as the higher-end P-lineup such as the P6600. The I-Class is further split down into 64-bit and 32-bit offerings, and the I7200 focuses on offering competitive solutions in the 32-bit line-up.
The I7200 markets itself as a processor especially adapted to the use-cases of real-time requirements present in communications systems, be in in traditional networking scenarios or wireless or mobile LTE/5G modem subsystems.
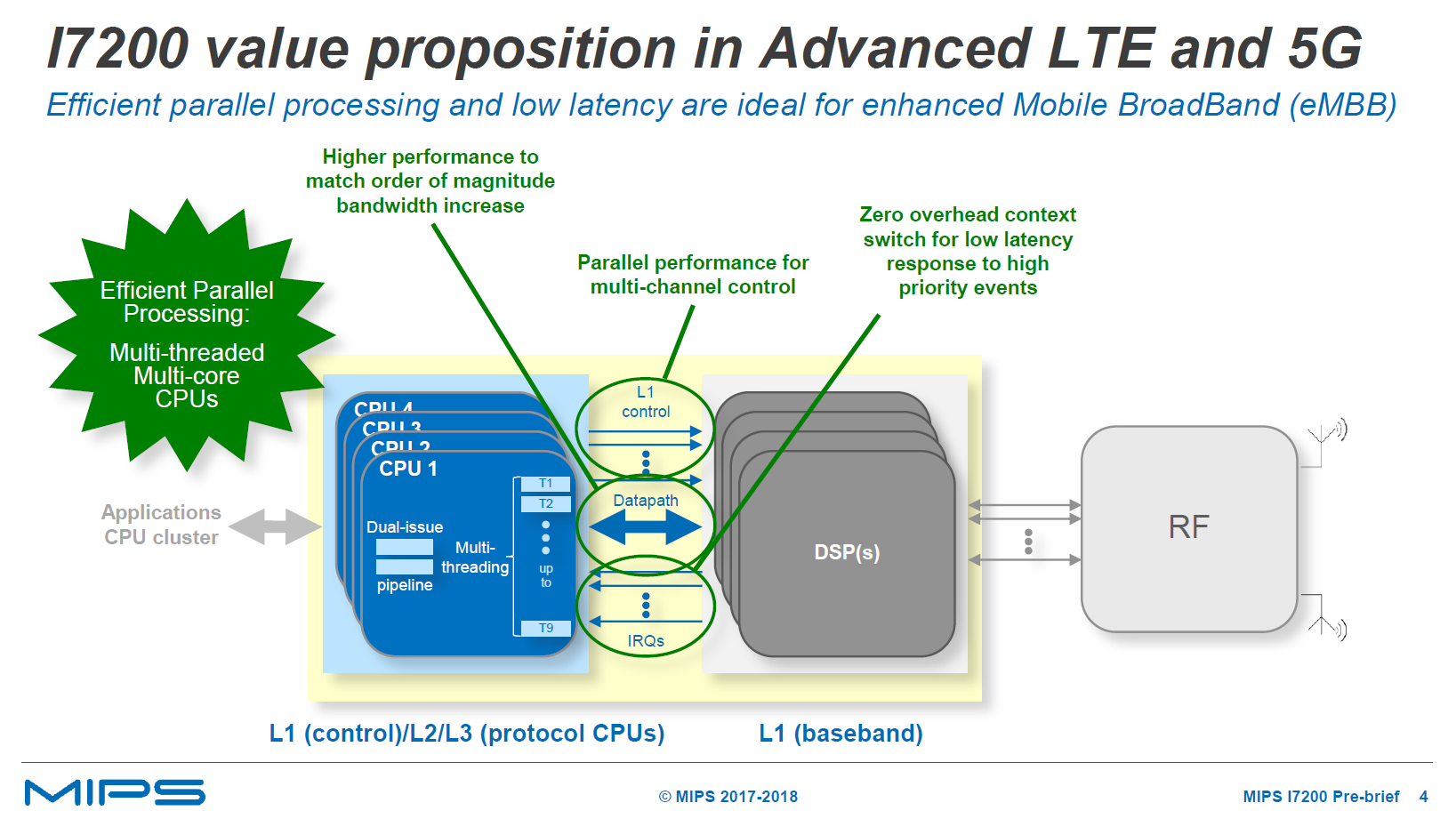
MIPS puts a great focus on the opportunity for the IP to shine in LTE-A and eMBB 5G modem subsystems where we’ll see an exponential increase in processing requirements on the control and protocol layers. The increased parallel performance as well as the special low-latency characteristics of the new MIPS core have been especially designed with such system requirements in mind.
The I7200 Architecture
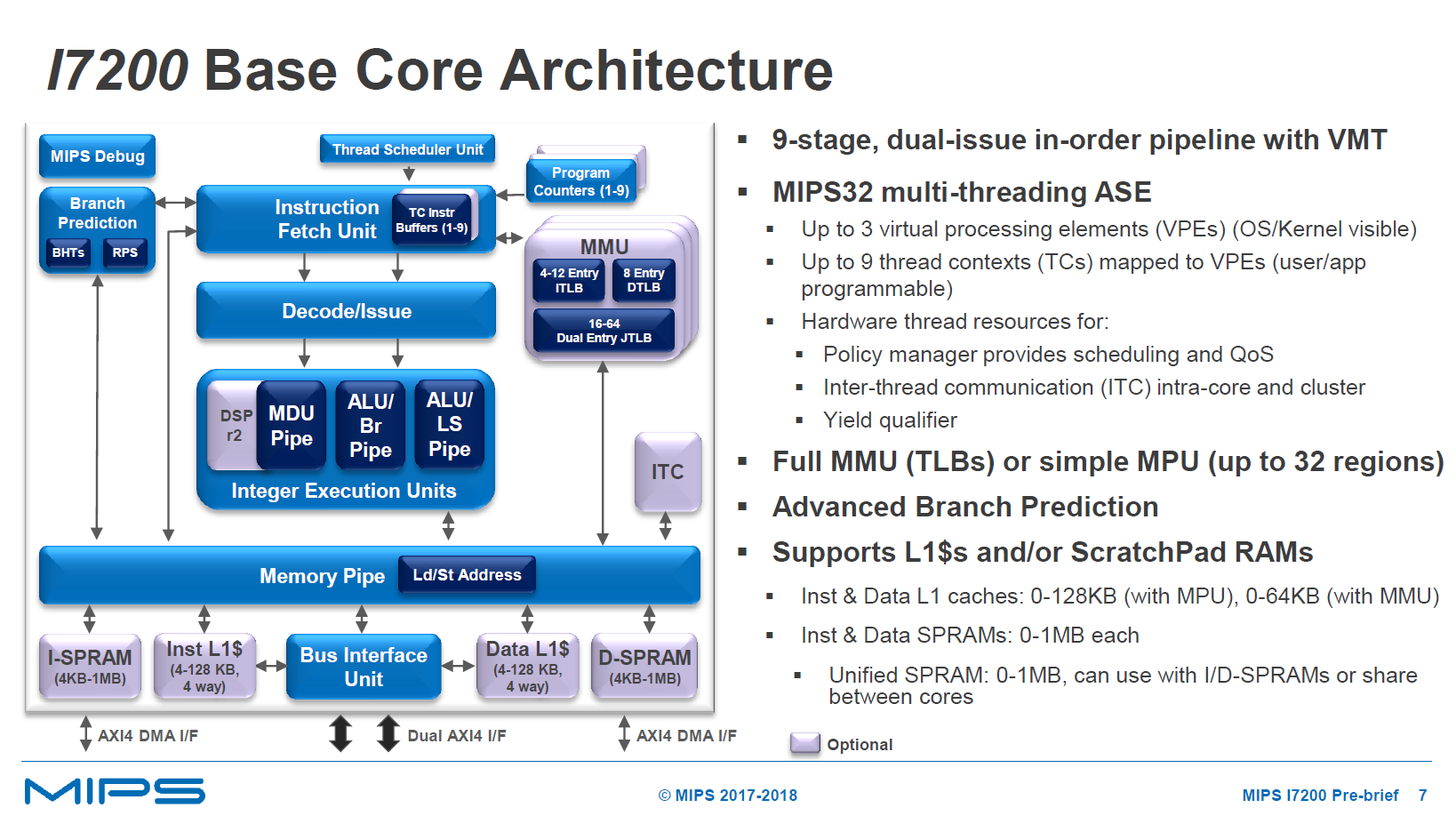
The I7200 follows past I-series CPUs in being in-order microarchitectures. The I7200 front-end has dual-decode/dual-issue that feeds three execution pipelines. The execution ports here feed a multiply/divide pipeline (MDU), and two ALU pipelines with respectively branching capabilities and load/store capabilities. The ALU/Br, ALU/LS pipelines can only operate one or the other kind of operation per clock. The µarch has a short pipeline length of 9 stages.
The special-sauce of MIPS CPUs has always been their multi-threading capabilities. The I7200 implements VMT (Vertical Multi-Threading) which is a variation of SMT (Simultaneous Multithreading). The key difference between the two is that SMT is targeted towards wider architectures and executes several threads at the same time spread over the execution units with the goal of increasing the EU utilisation. VMT on the other hand doesn’t execute two threads at the same time, but is able to efficiently switch between threads at extremely low context switch cost. This enables the core to alternate between threads using execution resources and memory access resources at clock-cycle granularity, and achieving better core utilisation this way.
The multi-threading ASE (Application specific extensions) includes two layers; VPEs (Virtual processing elements) and TCs (Thread contexts). The VPEs are visible to the operating system and act similarly as the SMT cores in desktop processors. The TCs however need special programming on the software side to be used. The I7200 is configurable from 1 to 3 VPEs and each VPE has 3 TCs – meaning in a full configuration a core can handle up to 9 threads, but again, only if the software takes advantage of the TCs.
Another defining characteristic of the I7200 is its ability to use ScratchPad RAMs. A core can be configured without, or with 4KB to 1MB instruction and data ScratchPad RAMs. These are not traditional caches but rather extremely low-latency memory which needs to be specifically programmed for in applications to make use of it. In embedded systems and real-time systems in particular there’s high usage of highly-specialised software so this is a key aspect of the core that enables its viability in RT use-cases.

In RT systems, the VMT capabilities of the core are especially useful for realising deterministic response times. For example, a software thread can be “parked” with already all relevant pre-loaded data resources and can be resumed and switched to with zero overhead on a context switch when needed and triggered by an event.
As mentioned before, the ScratchPad RAMs play a key role here as they offer tightly coupled memory that is critical for RT threads as it bypasses the system’s main memory system.

At the cluster level, we see integration up to 4 cores. We see the traditional configuration options here but again the key aspects here are the varying VPEs per core, and features such as an optional or up to 8MB L2 data cache. A large change here for MIPS is now the IP is natively supporting AMBA AXI4 and ACE interfaces instead of past OCP (Open core protocol) interfaces.
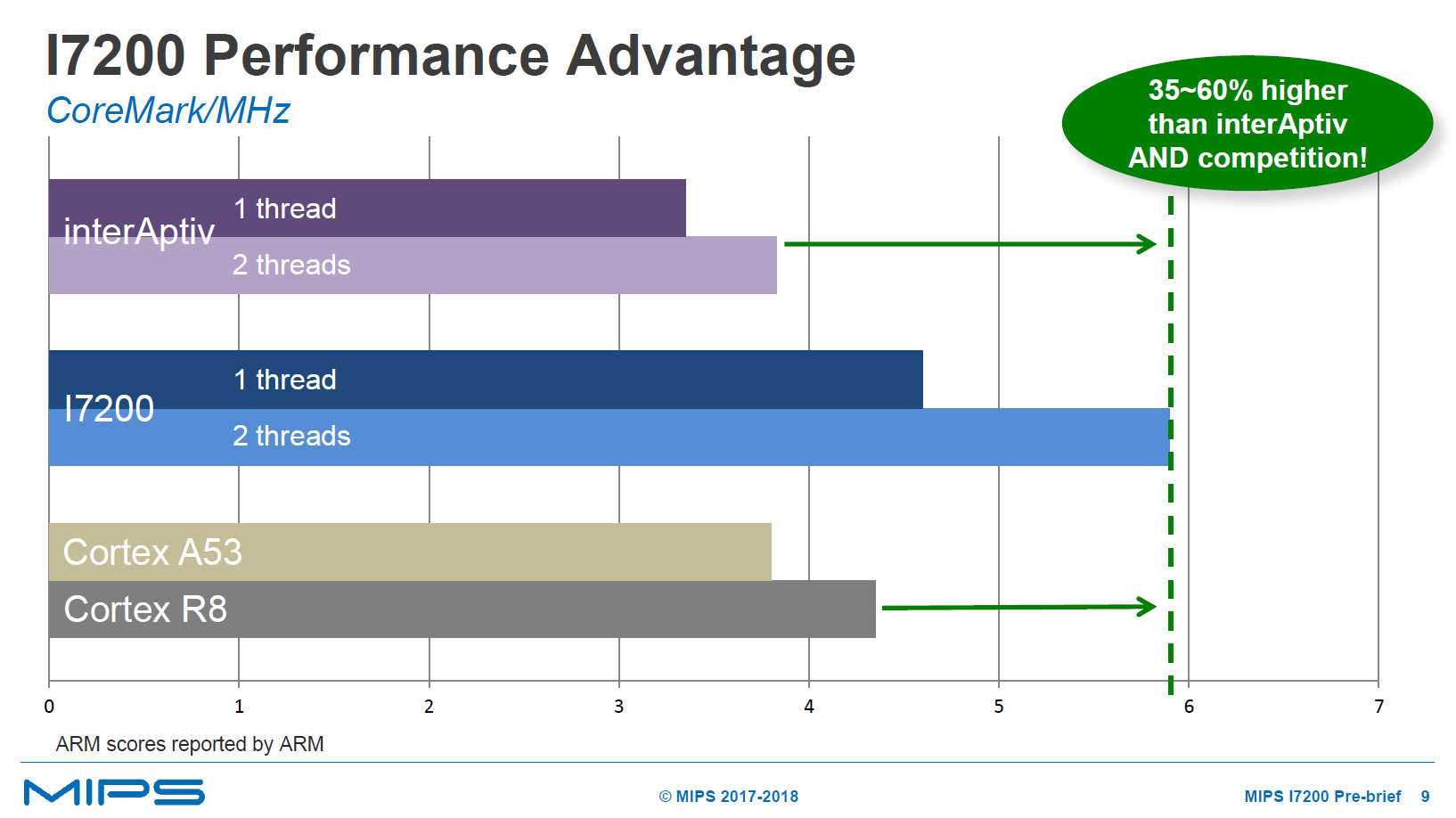
Performance wise the I7200 promises very large gains over the past interAptiv IPs, but also over ARM’s Cortex A53 and R8 processors. The Cortex R8 is more the direct competition for the I7200 as the A53 is aimed at application processor use-cases. The benchmark here is CoreMark as according to MIPS, it’s still very representative of real-world use-cases in the networking and communication spaces. The I7200 particularly posts a solid throughput improvement when it’s able to make use of several threads.
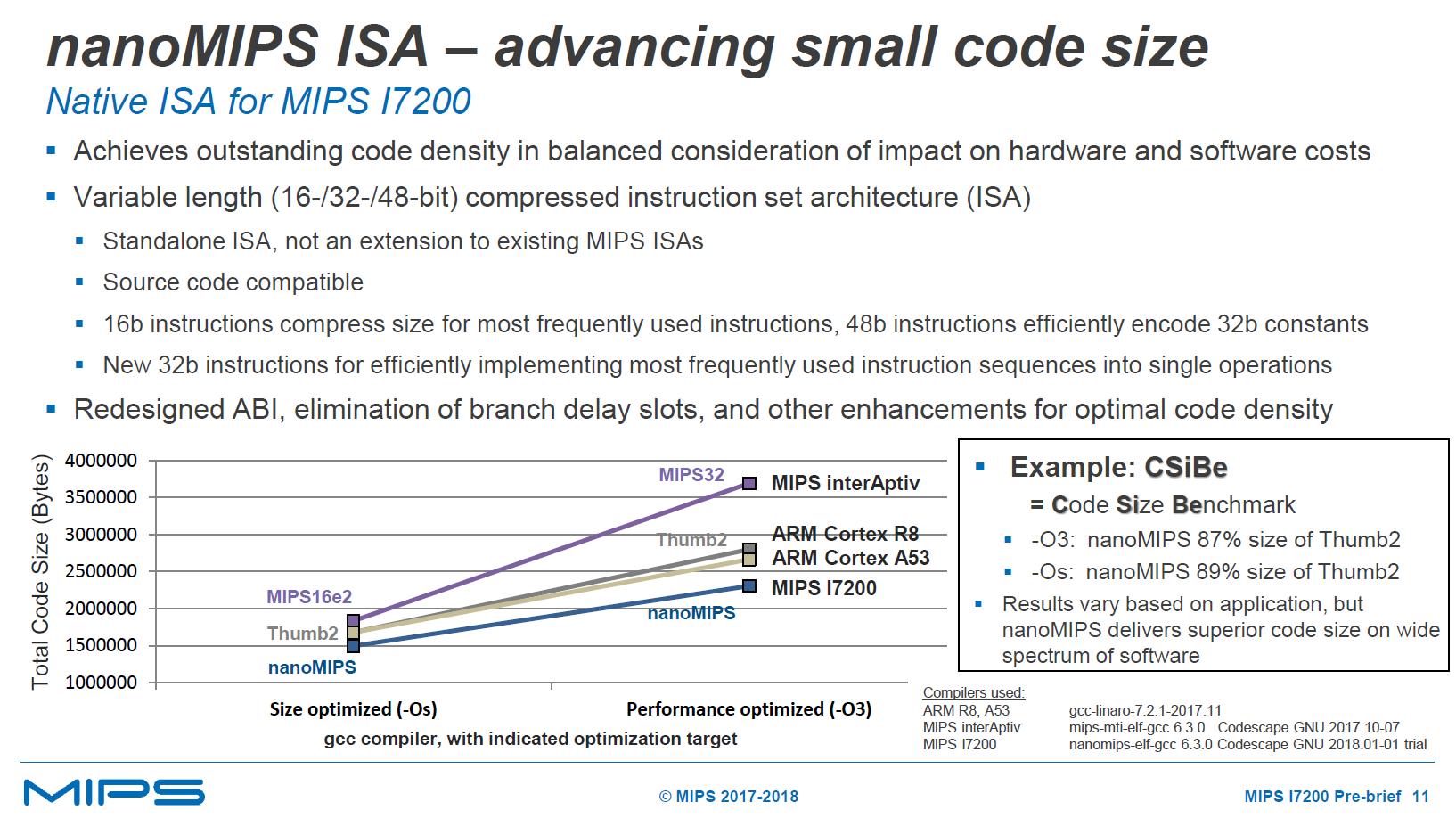
Another big news for the I7200 is that it’s actually introducing a new ISA. The native ISA for the core is nanoMIPS which is a newly designed 32-bit variable-length compressed instruction set. The main goals here is to achieve much better code sizes compared to past MIPS32 and MIPS16e2 ISAs. In the CSiBE (Code Size Benchmark) the new nanoMIPS ISA is able to produce the smallest code footprint, compared to previous MIPS implementations or ARM’s Thumb2. The advantage here is that in highly embedded systems memory is a large constraint; especially if you take into account that we’re dealing with limited resources such as the ScratchPAD RAMs of the I7200. Reducing code size improves both performance as well as power efficiency in this case, while enabling applications to be more complex given finite resources.
MIPS explained that the new ISA will live alongside MIPS64, but were relatively reserved to what this means to other variants such as MIPS32 – as it looks like the nanoMIPS would fully supercede products that implement 32-bit systems. It’s also to note that nanoMIPS is *not* compatible with previous ISAs and it requires a full new software stack, including new compiler systems. MIPS is said to have already the relevant software resources ready and they will be contributed openly following today’s announcements.
The new ISA is also a great pointer towards the direction where MIPS is heading, as seemingly they’re doubling down on the focus for embedded systems where software interoperability is not an issue. The company explains that in such systems the software stack is fully integrated so there is no great concern from customers if there are ISA changes. On the other hand it also means that the chances seem to be slim that the I7200 will be used as the general purpose processor in application processors, similarly to ARM’s Cortex A53 or A55.

Finally, MIPS publishes some implementation data on the I7200. On an 28nm process the core with 32KB L1I caches is quoted to come at 0.27mm², which is lower than the 0.33mm² which Arm quotes for a similarly configured Cortex R8. In terms of frequency, the I7200 is said to achieve up to 1.7 in worst case and 2.1GHz in typical corners on a 16FF+ process.
Today MIPS’s biggest success in the mobile space is in the adoption as the control processor in MediaTek’s in-house modems, as this was publicly announced last year. While avoiding mentioning any customer, MIPS divulged that the I7200 is being actively integrated into 5G systems by a major industry player. Naturally, that also means the design is released and available for licensing.








16 Comments
View All Comments
SaberKOG91 - Tuesday, May 1, 2018 - link
The same reason we use SMT. Inevitably all of your hardware threads will be out-numbered by software threads. The goal of SMT is to leverage unused cycles to execute multiple threads concurrently. The goal of VMT is to avoid introducing cycles when switching between non-concurrent threads. This is similar to how fine-grained multithreading worked on the last generations of UltraSPARC chips, except it is likely more flexible.I would disagree with the claim that VMT is a kind of SMT as they serve different purposes. VMT guarantees execution time for threads sharing a core (good for real-time scheduling) and it is also more predictable when instructions will run compared to SMT. Whereas, SMT just tries to get instructions through as quick as possible and there are no guarantees what order they are executed in, beyond the data dependency requirements.
TL;DR:
VMT is good for predictable and/or real-time execution of multiple SW threads; SMT is good for maximizing IPC at the expense of predictability.
jab701 - Tuesday, May 1, 2018 - link
In MIPS the VPE is a virtual processor, this is almost identical to how SMT. If you have a two core process or and two VPEs per core you have four logical cores. Simple...This MIPS processor supports 3 VPEs per core meaning 12 Logical processors on a 4 core system.The more complex bit is the VMT where you have TC's or thread contexts. MIPS has some special instructions to support this (provided it hasn't changed since I last worked with it). One instruction is called "fork". A programmer can call fork and pass an argument of a register with a memory address in it. The processor launches a new thread and starts executing at the address held in that register.
If you imagine you are processing network packets in real time. When a packet arrives, if you have a a spare thread which isn't running you can call fork and instantly start running a new thread and have that thread go off an process the packet. When it completes it can signal the main thread and exit via another special instruction.
This is quite a powerful technique for real-time systems. Last time I was working with MIPS processors Linux only saw Virtual cores (VPE's) but couldn't make use of the VMT or Thread context based instructions. It is a technique which only makes sense in real-time systems.
name99 - Tuesday, May 1, 2018 - link
I assume the real issue here is that the TC part of the VMT assumes a common address space. So you can cheaply swap between threads within the same app, but there is a cost to switching to a different app.User-level register state is duplicated (triplicated!) in hardware, but OS-level state (like memory mapping) is not.
peevee - Tuesday, May 1, 2018 - link
"L1I/$ caches"Andrei, it looks like they use "$" as a shorthand for "cache". So "L1$s" in their text means Level 1 caches.
Elstar - Tuesday, May 1, 2018 - link
Ya. Using "$" as shorthand for "cache" is a fairly common industry convention.watersb - Thursday, May 3, 2018 - link
VMT sounds a lot like PowerPC, low latency context switching. That made our radio front-end techs happy, back when I was working at a radio shop. This MIPS architecture feels like they have been listening to their LTE, 5G customers.