The Intel 12th Gen Core i9-12900K Review: Hybrid Performance Brings Hybrid Complexity
by Dr. Ian Cutress & Andrei Frumusanu on November 4, 2021 9:00 AM ESTFundamental Windows 10 Issues: Priority and Focus
In a normal scenario the expected running of software on a computer is that all cores are equal, such that any thread can go anywhere and expect the same performance. As we’ve already discussed, the new Alder Lake design of performance cores and efficiency cores means that not everything is equal, and the system has to know where to put what workload for maximum effect.
To this end, Intel created Thread Director, which acts as the ultimate information depot for what is happening on the CPU. It knows what threads are where, what each of the cores can do, how compute heavy or memory heavy each thread is, and where all the thermal hot spots and voltages mix in. With that information, it sends data to the operating system about how the threads are operating, with suggestions of actions to perform, or which threads can be promoted/demoted in the event of something new coming in. The operating system scheduler is then the ring master, combining the Thread Director information with the information it has about the user – what software is in the foreground, what threads are tagged as low priority, and then it’s the operating system that actually orchestrates the whole process.
Intel has said that Windows 11 does all of this. The only thing Windows 10 doesn’t have is insight into the efficiency of the cores on the CPU. It assumes the efficiency is equal, but the performance differs – so instead of ‘performance vs efficiency’ cores, Windows 10 sees it more as ‘high performance vs low performance’. Intel says the net result of this will be seen only in run-to-run variation: there’s more of a chance of a thread spending some time on the low performance cores before being moved to high performance, and so anyone benchmarking multiple runs will see more variation on Windows 10 than Windows 11. But ultimately, the peak performance should be identical.
However, there are a couple of flaws.
At Intel’s Innovation event last week, we learned that the operating system will de-emphasise any workload that is not in user focus. For an office workload, or a mobile workload, this makes sense – if you’re in Excel, for example, you want Excel to be on the performance cores and those 60 chrome tabs you have open are all considered background tasks for the efficiency cores. The same with email, Netflix, or video games – what you are using there and then matters most, and everything else doesn’t really need the CPU.
However, this breaks down when it comes to more professional workflows. Intel gave an example of a content creator, exporting a video, and while that was processing going to edit some images. This puts the video export on the efficiency cores, while the image editor gets the performance cores. In my experience, the limiting factor in that scenario is the video export, not the image editor – what should take a unit of time on the P-cores now suddenly takes 2-3x on the E-cores while I’m doing something else. This extends to anyone who multi-tasks during a heavy workload, such as programmers waiting for the latest compile. Under this philosophy, the user would have to keep the important window in focus at all times. Beyond this, any software that spawns heavy compute threads in the background, without the potential for focus, would also be placed on the E-cores.
Personally, I think this is a crazy way to do things, especially on a desktop. Intel tells me there are three ways to stop this behaviour:
- Running dual monitors stops it
- Changing Windows Power Plan from Balanced to High Performance stops it
- There’s an option in the BIOS that, when enabled, means the Scroll Lock can be used to disable/park the E-cores, meaning nothing will be scheduled on them when the Scroll Lock is active.
(For those that are interested in Alder Lake confusing some DRM packages like Denuvo, #3 can also be used in that instance to play older games.)
For users that only have one window open at a time, or aren’t relying on any serious all-core time-critical workload, it won’t really affect them. But for anyone else, it’s a bit of a problem. But the problems don’t stop there, at least for Windows 10.
Knowing my luck by the time this review goes out it might be fixed, but:
Windows 10 also uses the threads in-OS priority as a guide for core scheduling. For any users that have played around with the task manager, there is an option to give a program a priority: Realtime, High, Above Normal, Normal, Below Normal, or Idle. The default is Normal. Behind the scenes this is actually a number from 0 to 31, where Normal is 8.
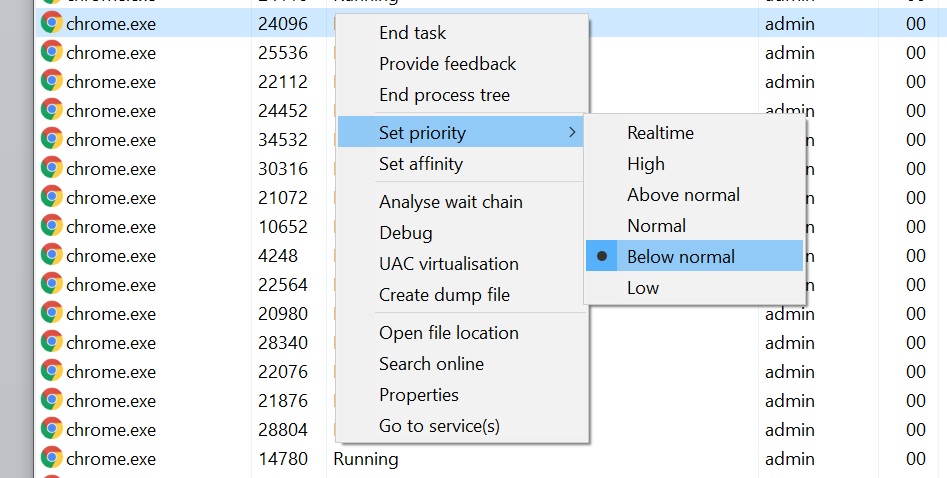
Some software will naturally give itself a lower priority, usually a 7 (below normal), as an indication to the operating system of either ‘I’m not important’ or ‘I’m a heavy workload and I want the user to still have a responsive system’. This second reason is an issue on Windows 10, as with Alder Lake it will schedule the workload on the E-cores. So even if it is a heavy workload, moving to the E-cores will slow it down, compared to simply being across all cores but at a lower priority. This is regardless of whether the program is in focus or not.
Of the normal benchmarks we run, this issue flared up mainly with the rendering tasks like CineBench, Corona, POV-Ray, but also happened with yCruncher and Keyshot (a visualization tool). In speaking to others, it appears that sometimes Chrome has a similar issue. The only way to fix these programs was to go into task manager and either (a) change the thread priority to Normal or higher, or (b) change the thread affinity to only P-cores. Software such as Project Lasso can be used to make sure that every time these programs are loaded, the priority is bumped up to normal.








474 Comments
View All Comments
Foeketijn - Thursday, November 4, 2021 - link
So much energy is put into designing an efficient package. And the result is a packege that churns out even more engergy then the designing took.Even the biggest aircoolers will struggle to keep this cool enough under load. Don't even start about power price and carbon footprint. Worst part being for intel, They can't use this design to gain back some territory in the HEDT and server market. AMD can double the poweroutput for an Epyc or TR. That is not optional for Intel. Lets wait for the tock.
Wrs - Thursday, November 4, 2021 - link
How does Sapphire Rapids exist then?Spunjji - Friday, November 5, 2021 - link
Different design!kgardas - Thursday, November 4, 2021 - link
Great article! I especially appreciate avx512 related bits. Honestly it would be great if Intel recover from this chaos and enable avx512 in their adl-derived xeons (E-xxxx).Slash3 - Thursday, November 4, 2021 - link
This is almost certainly part of their plan.Drumsticks - Thursday, November 4, 2021 - link
Doesn't the efficiency of the product just go out the window because Intel is effectively setting the sustained performance power limit at 240W? Obviously this has an impact for consumers, as it's the power draw they will see, but for the purposes of analyzing the architecture or the process node, it doesn't seem like a great way to draw conclusions. There was a test floating around pre-NDA where the PL1 was fixed to 125/150/180/240W, and it looked like the last +60% power draw only gained +8% performance.To be sure, I'm sure Intel did it because they need that last 8% to beat the 5950X semi-consistently, and most desktop users won't worry about it too much. But if you want to analyze how efficient the P-core architecture + Intel 7 is, wouldn't it make sense to lower the sustained power limit? It's just like clocking anything else at the top of its DVFS curve - I'm sure if it was possible to set Zen 3 to a 240W power limit, we would find it wasn't nearly as efficient as Zen 3 at 141W.
abufrejoval - Thursday, November 4, 2021 - link
I have to agree with Charlie Demerjian: the sane choices for desktop parts would have been 10 P-cores on one chip and 40 E-cores on another for an edge server part.Then again for gaming clearly another set of P-cores could have been had from the iGPU, which even at only 32EU is just wasted silicon on a gaming desktop. Intel evidently doesn't mind nearly as much as AMD doing physically different dies so why not use that? (Distinct server SKUs come to mind)
Someone at Intel clearly clearly desperate enough to aim for some new USP and they even sacrified AVS-512 for (or just plain sanity) for that.
Good to see that Intel was able to reap additional instructions from every clock in a P-core (that's the true miracle!).
But since I am still running quite a few Skylake and even Haswell CPUs (in fact typing on a Haswell Xeon server doing double duty as always-on workstation), I am quite convinced that 4GHz Skylake is "good enough" for a huge amount of compute time and would really rather use all that useless E-core silicon to replace my army of Pentium J5005 Atoms, which are quite far from delivering that type of computing power on perhaps more of an electricity budget.
name99 - Friday, November 5, 2021 - link
I think most analyses (though not Charlie's) are missing Intel's primary concern here.For THESE parts, Intel is not especially interested in energy saving. That may come with the laptop parts, but for these parts the issue is that Intel wants OPTIONALITY: they want a single part that does well on single threaded (and the real-world equivalent now of 2-3 threaded once you have UI and OS stuff on separate threads) code, AND on high throughput (ie extremely threaded) code.
In the past SMT has provided this optionality; now, ADL supposedly extends it -- if you can get 4*.5x throughput for a cluster vs 2*.7x throughput for SMT on a large core, you're area-ahead with a cluster -- but you still need large cores for large core jobs. That's the balance INTC is trying to straddle.
Now compare with the other two strategies.
- For AMD, with chiplets and a high-yielding process, performance/unit area has not been a pressing concern. They're able to deliver a large number of P cores, giving you both latency (ues a few P cores) or throughput (use a lot of P cores). This works fine for server or desktop, but
+ it's not a *great* server solution. It uses too much area for server problems that are serious throughput problems (ie the area that ARM even in its weak Graviton2 and Ampere versions covers so well)
+ it does nothing for laptops. Presumably Intel's solution for laptops is not to drive the E-cores nearly as hard, which is not a great solution (compare to Apple's energy or power numbers) but better than nothing -- and certainly better than AMD.
- For Apple there is the obvious point that their P cores are great as latency cores (and "low enough" area if they feel it appropriate to add more) and their E cores great as energy cores. More interesting is the throughput question. Here I think, in true Apple fashion, they have zigged where others have zagged. Apple's solution to throughput is to go all-in on GPGPU!
For their use cases this is not at all a crazy idea. There's a reason GPGPU was considered the hot new thing a while ago, and of course nV are trying equally hard to push this idea. GPGPU works very well for most image-type stuff, for most AI/ML stuff, even for a reasonable fraction of physics/engineering problems. If you have decent tools (and Apple's combination of XCode and Metal Compute seems to be decent enough -- if you don't go in determined to hate them because they're not what you're used to whether that's CUDA or OpenCL) then GPGPU works for a lot of code.
What GPGPU *doesn't work for* is server-type throughput; no-one's saying "I really need to port HHVM, or ngingx, to a GPU and then, man, things will sing". But of course why should Apple care? They're not selling into that market (yet...)
So ultimately
- Intel are doing this because it gives them
+ better optionality on the desktop
+ lower (not great, but lower) energy usage in the laptop
+ MANUFACTURING optionality at the server. They can announce essentially a XEON-P line with only P cores, and a Xeon-E line with ?4? cores (to run the OS) and 4x as many E cores as the same-sized Xeon-P, and compete a little better with the ARM servers in the extreme throughput space.
- AMD are behind conceptually. They have their one hammer of a chiplet with 16 cores on it, and it was a good hammer for a few years. But either they missed the value of also owning a small-area core, or just didn't have the resources. Either way they're behind right now.
- Apple remain in the best position -- both for their needs, but also to grow in any direction. They can keep going downward and sideways (watch, phone, glasses, airpods...) with E cores. They can maintain their current strengths with P cores. They can make (either for specialized macs, or for their own internal use) the equivalent of an M1 Max only with a sea of E cores rather than a sea of GPU that would be a very nice target for a lot of server work. And they likely have in mind, long-term, essentially democratizing CUDA, moving massive GPGPU off crazy expensive nV rigs existing at the department level down to something usable by any individual -- basically a replay of the VAX to SparcStation sort of transition.
I think INTC are kinda, in their massive dinosaur way, aware of this hence all the talking up of Xe, PV and OneAPI; but they just will not be able to execute rapidly enough. They have the advantage that Apple started years behind, but Apple moves at 3x their speed.
nV are well aware of the issue, but without control of a CPU and a SoC, what can they do? They can keep trying to make CUDA and their GPU's better, but they're crippled by the incompetence of the CPU vendors.
AMD? Oh poor AMD. Always in this horrible place where they do what they can do pretty well -- but simply do not have the resources to grow along all the directions they need to grow simultaneously. Just like their E-core response will be later than ideal (and probably a sub-optimal scramble), so too their response to this brave new world of extreme-throughput via extreme GPGPU...
NikosD - Friday, November 5, 2021 - link
According to the latest rumors of MLID (that most of the times have been proved true) AMD's reply to E-cores is Zen 4D (D for Dense, not dimensions).Zen 4D core is a stripped-down Zen 4 core, with less cache and lower IPC, but smaller die area and less power consumption, leading to a 16 core CCD.
Also, Zen 4 core is expected to have a lot higher IPC than Alder Lake and Zen 3/3D, so it seems more than capable to compete with Raptor Lake (next Intel's architecture) this time next year.
AMD is not going to lose performance crown in the next few years.
Spunjji - Friday, November 5, 2021 - link
AMD don't *need* E cores, though? You said "it does nothing for laptops", but they're doing fine there - Zen 3 with 8 cores at 15W gives a great balance of ST and MT performance that Intel can't really touch (yet), and the die area is pretty good too. Intel need E cores to compete, AMD don't (yet).Zen 4D is reportedly going to be their answer to "E" cores, and it's probably going to cause fewer issues than having fully heterogeneous cores.