The Intel 12th Gen Core i9-12900K Review: Hybrid Performance Brings Hybrid Complexity
by Dr. Ian Cutress & Andrei Frumusanu on November 4, 2021 9:00 AM ESTFundamental Windows 10 Issues: Priority and Focus
In a normal scenario the expected running of software on a computer is that all cores are equal, such that any thread can go anywhere and expect the same performance. As we’ve already discussed, the new Alder Lake design of performance cores and efficiency cores means that not everything is equal, and the system has to know where to put what workload for maximum effect.
To this end, Intel created Thread Director, which acts as the ultimate information depot for what is happening on the CPU. It knows what threads are where, what each of the cores can do, how compute heavy or memory heavy each thread is, and where all the thermal hot spots and voltages mix in. With that information, it sends data to the operating system about how the threads are operating, with suggestions of actions to perform, or which threads can be promoted/demoted in the event of something new coming in. The operating system scheduler is then the ring master, combining the Thread Director information with the information it has about the user – what software is in the foreground, what threads are tagged as low priority, and then it’s the operating system that actually orchestrates the whole process.
Intel has said that Windows 11 does all of this. The only thing Windows 10 doesn’t have is insight into the efficiency of the cores on the CPU. It assumes the efficiency is equal, but the performance differs – so instead of ‘performance vs efficiency’ cores, Windows 10 sees it more as ‘high performance vs low performance’. Intel says the net result of this will be seen only in run-to-run variation: there’s more of a chance of a thread spending some time on the low performance cores before being moved to high performance, and so anyone benchmarking multiple runs will see more variation on Windows 10 than Windows 11. But ultimately, the peak performance should be identical.
However, there are a couple of flaws.
At Intel’s Innovation event last week, we learned that the operating system will de-emphasise any workload that is not in user focus. For an office workload, or a mobile workload, this makes sense – if you’re in Excel, for example, you want Excel to be on the performance cores and those 60 chrome tabs you have open are all considered background tasks for the efficiency cores. The same with email, Netflix, or video games – what you are using there and then matters most, and everything else doesn’t really need the CPU.
However, this breaks down when it comes to more professional workflows. Intel gave an example of a content creator, exporting a video, and while that was processing going to edit some images. This puts the video export on the efficiency cores, while the image editor gets the performance cores. In my experience, the limiting factor in that scenario is the video export, not the image editor – what should take a unit of time on the P-cores now suddenly takes 2-3x on the E-cores while I’m doing something else. This extends to anyone who multi-tasks during a heavy workload, such as programmers waiting for the latest compile. Under this philosophy, the user would have to keep the important window in focus at all times. Beyond this, any software that spawns heavy compute threads in the background, without the potential for focus, would also be placed on the E-cores.
Personally, I think this is a crazy way to do things, especially on a desktop. Intel tells me there are three ways to stop this behaviour:
- Running dual monitors stops it
- Changing Windows Power Plan from Balanced to High Performance stops it
- There’s an option in the BIOS that, when enabled, means the Scroll Lock can be used to disable/park the E-cores, meaning nothing will be scheduled on them when the Scroll Lock is active.
(For those that are interested in Alder Lake confusing some DRM packages like Denuvo, #3 can also be used in that instance to play older games.)
For users that only have one window open at a time, or aren’t relying on any serious all-core time-critical workload, it won’t really affect them. But for anyone else, it’s a bit of a problem. But the problems don’t stop there, at least for Windows 10.
Knowing my luck by the time this review goes out it might be fixed, but:
Windows 10 also uses the threads in-OS priority as a guide for core scheduling. For any users that have played around with the task manager, there is an option to give a program a priority: Realtime, High, Above Normal, Normal, Below Normal, or Idle. The default is Normal. Behind the scenes this is actually a number from 0 to 31, where Normal is 8.
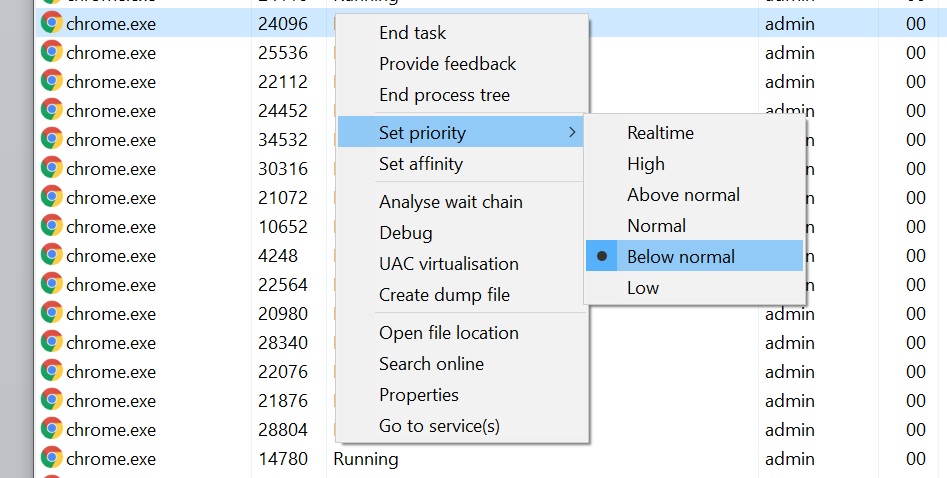
Some software will naturally give itself a lower priority, usually a 7 (below normal), as an indication to the operating system of either ‘I’m not important’ or ‘I’m a heavy workload and I want the user to still have a responsive system’. This second reason is an issue on Windows 10, as with Alder Lake it will schedule the workload on the E-cores. So even if it is a heavy workload, moving to the E-cores will slow it down, compared to simply being across all cores but at a lower priority. This is regardless of whether the program is in focus or not.
Of the normal benchmarks we run, this issue flared up mainly with the rendering tasks like CineBench, Corona, POV-Ray, but also happened with yCruncher and Keyshot (a visualization tool). In speaking to others, it appears that sometimes Chrome has a similar issue. The only way to fix these programs was to go into task manager and either (a) change the thread priority to Normal or higher, or (b) change the thread affinity to only P-cores. Software such as Project Lasso can be used to make sure that every time these programs are loaded, the priority is bumped up to normal.








474 Comments
View All Comments
abufrejoval - Friday, November 5, 2021 - link
First of all, thanks for the exhaustive answer!I get the E/P core story in general, especially where a battery or “the edge” constrain power envelopes. I don’t quite get the benefit of a top-of-the-line desktop SoC serving as a demonstration piece for the concept.
What Intel seems to be aiming for is a modular approach where you can have “lots” or “apartments” of die area dedicated to GPU, P-cores and E-cores. Judging from the ADL die shots very roughly you can get 4 E-cores or 32 iGPU EUs from the silicon real-estate of a P-core (or 16EU + media engine). And with Intel dies using square process yields to go rectangular, you just get a variable number of lots per die variant.
Now, unfortunately, these lots can’t be reconfigured (like an FPGA) between these usage types, so you have to order and pick the combination that suits your use case and for the favorite Anandtech gamer desktop that comes out as 12 P-cores, zilch E-core, iGPU or media engine. I could see myself buying that, if I didn’t already have a 5950x sitting in that slot. I can also very much see myself buying a 2 P-core + 40 E-core variant at top bin for the same €600, using the very same silicon real-estate as the ADL i9.
Intel could (and should) enable this type of modularity in manufacturing. With a bit of tuning to their fabs they should be able to mix lot allocations across the individual dies in a wafer. The wafer as such obviously needs to be set up for a specific lot size, but what you use to fill the lots is a choice of masks.
You then go into Apple’s silicon and I see Apple trying their best to fill a specific niche with three major options, the M1, the M1Pro and the M1Max. None of these cater to gamers or cloud service providers. When it comes to HPC, max ML training performance or most efficient ML inference, their design neither targets nor serves those workloads. Apple targets media people working on the move. For that audience I can see them offer an optimal fit, that no x86-dGPU combo can match (on battery). I admire their smart choice of using 8 32-bit DRAM channels to obtain 400GB/s of bandwidth on DDR4 economy in the M1Max, but it’s not generalizable across their niche workloads. Their ARM core seems an amazing piece of kit, but when the very people who designed it thought to branch out into edge servers, they were nabbed to do better mobile cores instead… The RISC-V people will tell you about the usefulness of a general-purpose CPU focus.
I’ve been waiting for an Excel refactoring ever since Kaveri introduced heterogeneous computing, with function-level GPU/CPU paradigm changes and pointer compatibility. I stopped holding my breath for this end-user GPGPU processing.
On the machine learning side, neuromorphic hardware and wafer-scale whatnot will dominate training, for inference dedicated IP “lots” also seem the better solution. I simply don’t see Apple having any answer or relevance outside their niche, especially since they won’t sell their silicon to the open market.
I’m pretty sure you could build a nice gaming console from M1Max silicon, if they offered it at X-Box prices, but GPT-4++ won’t be trained on Apple silicon and inference needs to run on mobile, 5 Watts max and only for milliseconds.
lejeczek - Thursday, November 4, 2021 - link
Well..I mean... it's almost winter so... having problems with central heating? or thought: I'd warm up the garage? There is your answer (has been for a while) ... all you need to do - just give it a full load.abufrejoval - Saturday, November 6, 2021 - link
Just decided to let Microsoft's latest Flight Simulator update itself over night. I mean it's a Steam title,right? But it won't use Steam mechanisms for the updates, which would obviously make it much faster and more efficient, so instead you have to run the updates in-game and they just a) linearize everything on a single core, b) thus take forever even if you have fast line, c) leave the GPU running full throttle on the main menu, eating 220Watts on my 2080ti for a static display... (if there ever has been an overhyped and underperforming title the last decade or two, that one gets my nomination every time I want to fly instead of updating).Small wonder I woke up with a dry throat this morning and the machine felt like a comfy coal oven from way back then, when there was no such thing as central heating and that's how you got through winter (no spring chicken, me).
abufrejoval - Thursday, November 4, 2021 - link
Oh no! Set carry flag and clear carry flag are gone! How will we manage without them?Having to deal with the loss of my favorite instuction (AAA, which always stood out first) was already had to deal with, but there it was easier to accept that BCD (~CoBoL style large number arithmetic) wasn't going to remain popular on a 64-Bit CPU with the ability to do some type of integer arithmetic with 512-Bit vectors.
But this looks like the flag register, a dear foe of RISC types, who loved killing it, is under attack!
It's heartening to see that not all CISC is lost since they are improving the x86 gene pool with improving wonderful things like REP cmpsb and REP scasb, which I remember hand-coding via ASM statements on Turbo-C for my 80286: Ah, the things microcode could do!
It even inspired this kid from Finland to think of writing a Unix like kernel, because a task switch could be coded by doing a jump on a task state segement... He soon learned that while the instruction was short on paper, the three page variant from BSD and L4 guys was much faster than Intel's microcode!
He learned to accept others can actually code better than him and that lesson may have been fundamental to the fate of everything Linux has effected.
cyrusfox - Thursday, November 4, 2021 - link
Great initial review! So many good nuggets in here. Love that AVX512 bit as well as breaking down the cores individually. Alder lake mobile is going to be awesome! DDR5 upgrade sure is tempting, showing tangible benefit, most applications neutral, something to chew on While I figure out if I am going to get a i5 or i9 to replace my i9-10850k.Request:
Will anyone please do a review of iGPU Rocketlake vs Alder Laker. I know it is "identical design" (Intel Xe 32EU) but different node: 14nm vs 10nm/7 (Still not a fan of the rename...)
UHD 770 vs UHD 750 showdown! Biggest benefit to Intel right now during these still inflated GPU times.
abufrejoval - Thursday, November 4, 2021 - link
Eventually someone might actually do that. But don't expect any real difference, nor attractive performance. There have been extensive tests on the 96EU variant in Tiger Lake and 32EU are going to be 1/3 of that rather modest gaming performance.The power allocation to the iGPUs tends to be "prioritized", but very flat after that. So, if both iGPU and CPU performance are requested, the iGPU tends to win, but then very quickly stops to benefit after it has received its full share, while CPU core fight for everything left in the TDP pie.
That's why iGPU performance say on a Tiger Lake H 45Watt SoC won't be noticeably better than on a 15Watt Tiger Lake U.
The eeny-meeny 32EU Xe will double your UHD 650-750 performance and reach perhaps the equivalent of an Iris 550-650 with 48EU and eDRAM, but that's it.
I'd have put another two P-cores in that slice of silicon...
Roddybabes - Thursday, November 4, 2021 - link
Not too impressive for a next gen CPU on a supposedly better process node and a newly designed architecture. TechSpot's ten game average for 1080p high quality only put the i9-12900K ahead of the R9 5950X by just 2.6% (7.4% for 1% lows). If AMD's claim of V-cache adding 15% to average gaming results is true, that would give AMD an average lead of 12.4% (7.6% for 1% lows) for the same year-old design with V-cache and still using last generation DDR4 memory - now that is what I would call impressive.If you have to have top-line FPS and 1% lows, it seems that it would be prudent to just wait a little while longer for what AMD is currently cooking in its ovens.
https://www.techspot.com/review/2351-intel-core-i9...
kwohlt - Friday, November 5, 2021 - link
"supposedly better process node"I mean, considering 12900K is nearly doubling 11900K's multicore performance while consuming 20% less power, I'd say Intel 7 is certainly a large perf/watt improvement over Intel 14nm
But also, efficiency comes from more than just process node. Core architecture plays a role.
Roddybabes - Friday, November 5, 2021 - link
I agree that the performance increase over the 11900K is great but the real competition is not Intel's previous generation but AMD's current offerings. eddmann said in an earlier post about i9-12900K's PL1 performance: You can have ~92% of the performance for ~68% of the power - see link below.https://twitter.com/TweakPC/status/145596164928275...
In essence, for the benchmark in question, if Intel had set max PL1 limit to just 150W, that processor would have amazing power efficency. But guess what, Intel needed that 8% of additional perfomance to give the i9 daylight in the benchmarks, so that 68% of additional power was needed. It would be interesting to see if Intel decides to offer E variants of its top-line CPUs as they would prove to be super efficient.
From the Alderlake CPUs launched, it would seem that the i5-12600K hits AMD the hardest; it will be interesting to see how AMD responds.
Mr Perfect - Thursday, November 4, 2021 - link
You know, I didn't even notice your testbeds all still had SATA drives in them. I just assumed they'd be using whatever was contemporary for the system. This does make me wonder how often a modern benchmark has results that aren't quite what they'll be for users who actually use them. Guess we'll find out in Q2!