The Intel 12th Gen Core i9-12900K Review: Hybrid Performance Brings Hybrid Complexity
by Dr. Ian Cutress & Andrei Frumusanu on November 4, 2021 9:00 AM ESTFundamental Windows 10 Issues: Priority and Focus
In a normal scenario the expected running of software on a computer is that all cores are equal, such that any thread can go anywhere and expect the same performance. As we’ve already discussed, the new Alder Lake design of performance cores and efficiency cores means that not everything is equal, and the system has to know where to put what workload for maximum effect.
To this end, Intel created Thread Director, which acts as the ultimate information depot for what is happening on the CPU. It knows what threads are where, what each of the cores can do, how compute heavy or memory heavy each thread is, and where all the thermal hot spots and voltages mix in. With that information, it sends data to the operating system about how the threads are operating, with suggestions of actions to perform, or which threads can be promoted/demoted in the event of something new coming in. The operating system scheduler is then the ring master, combining the Thread Director information with the information it has about the user – what software is in the foreground, what threads are tagged as low priority, and then it’s the operating system that actually orchestrates the whole process.
Intel has said that Windows 11 does all of this. The only thing Windows 10 doesn’t have is insight into the efficiency of the cores on the CPU. It assumes the efficiency is equal, but the performance differs – so instead of ‘performance vs efficiency’ cores, Windows 10 sees it more as ‘high performance vs low performance’. Intel says the net result of this will be seen only in run-to-run variation: there’s more of a chance of a thread spending some time on the low performance cores before being moved to high performance, and so anyone benchmarking multiple runs will see more variation on Windows 10 than Windows 11. But ultimately, the peak performance should be identical.
However, there are a couple of flaws.
At Intel’s Innovation event last week, we learned that the operating system will de-emphasise any workload that is not in user focus. For an office workload, or a mobile workload, this makes sense – if you’re in Excel, for example, you want Excel to be on the performance cores and those 60 chrome tabs you have open are all considered background tasks for the efficiency cores. The same with email, Netflix, or video games – what you are using there and then matters most, and everything else doesn’t really need the CPU.
However, this breaks down when it comes to more professional workflows. Intel gave an example of a content creator, exporting a video, and while that was processing going to edit some images. This puts the video export on the efficiency cores, while the image editor gets the performance cores. In my experience, the limiting factor in that scenario is the video export, not the image editor – what should take a unit of time on the P-cores now suddenly takes 2-3x on the E-cores while I’m doing something else. This extends to anyone who multi-tasks during a heavy workload, such as programmers waiting for the latest compile. Under this philosophy, the user would have to keep the important window in focus at all times. Beyond this, any software that spawns heavy compute threads in the background, without the potential for focus, would also be placed on the E-cores.
Personally, I think this is a crazy way to do things, especially on a desktop. Intel tells me there are three ways to stop this behaviour:
- Running dual monitors stops it
- Changing Windows Power Plan from Balanced to High Performance stops it
- There’s an option in the BIOS that, when enabled, means the Scroll Lock can be used to disable/park the E-cores, meaning nothing will be scheduled on them when the Scroll Lock is active.
(For those that are interested in Alder Lake confusing some DRM packages like Denuvo, #3 can also be used in that instance to play older games.)
For users that only have one window open at a time, or aren’t relying on any serious all-core time-critical workload, it won’t really affect them. But for anyone else, it’s a bit of a problem. But the problems don’t stop there, at least for Windows 10.
Knowing my luck by the time this review goes out it might be fixed, but:
Windows 10 also uses the threads in-OS priority as a guide for core scheduling. For any users that have played around with the task manager, there is an option to give a program a priority: Realtime, High, Above Normal, Normal, Below Normal, or Idle. The default is Normal. Behind the scenes this is actually a number from 0 to 31, where Normal is 8.
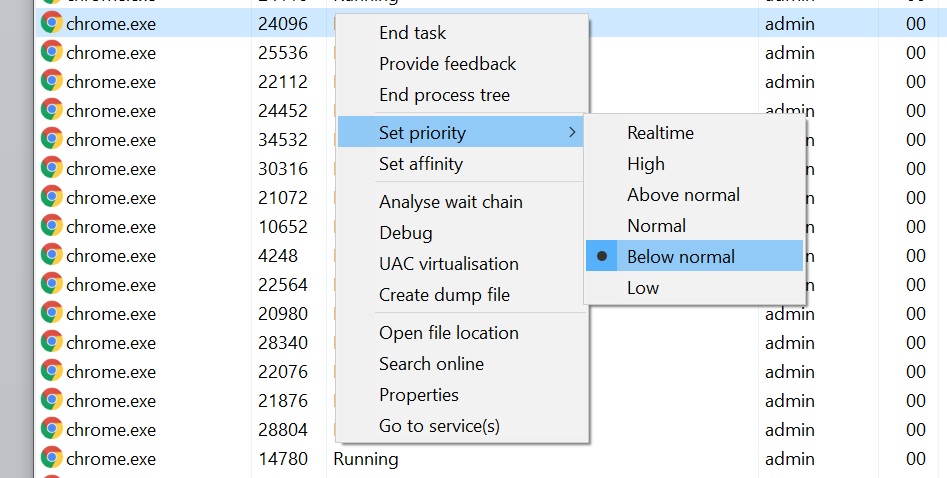
Some software will naturally give itself a lower priority, usually a 7 (below normal), as an indication to the operating system of either ‘I’m not important’ or ‘I’m a heavy workload and I want the user to still have a responsive system’. This second reason is an issue on Windows 10, as with Alder Lake it will schedule the workload on the E-cores. So even if it is a heavy workload, moving to the E-cores will slow it down, compared to simply being across all cores but at a lower priority. This is regardless of whether the program is in focus or not.
Of the normal benchmarks we run, this issue flared up mainly with the rendering tasks like CineBench, Corona, POV-Ray, but also happened with yCruncher and Keyshot (a visualization tool). In speaking to others, it appears that sometimes Chrome has a similar issue. The only way to fix these programs was to go into task manager and either (a) change the thread priority to Normal or higher, or (b) change the thread affinity to only P-cores. Software such as Project Lasso can be used to make sure that every time these programs are loaded, the priority is bumped up to normal.








474 Comments
View All Comments
mode_13h - Saturday, November 6, 2021 - link
> the only way I think they can remedy this is by designing a new core from scratchI'm not sure I buy this narrative. In the interview with AMD's Mike Clark, he said AMD takes a fresh view of each new generation of Zen and then only reuses what old parts still fit. As Intel is much bigger and better-resourced, I don't see why their approach would fundamentally differ.
> or scaling Gracemont to target Zen 4 or 5.
I don't understand this. The E-cores are efficiency-oriented (and also minimize area, I'd expect). If you tried to optimize them for performance, they'd just end up looking & behaving like the P-cores.
GeoffreyA - Sunday, November 7, 2021 - link
I stand by my view that designing a CPU from scratch will bring benefit, while setting them back temporarily. Of course, am no expert, but it's reasonable to guess that, no matter how much they change things, they're still being restricted by choices made in the Pentium Pro era. In the large, sweeping points of the design, it's similar, and that is exerting an effect. Start from scratch, and when you reach Golden Cove IPC, it'll be at lower power I think. Had AMD gone on with K10, I do not doubt it would never have achieved Zen's perf/watt. Sometimes it's best to demolish the edifice and raise it again, not going to the opposite extreme of a radical departure.As for the E-cores, if I'm not mistaken, they're at greater perf/watt than Skylake, reaching the same IPC more frugally. If that's the case, why not scale it up a bit more, and by the time it reaches GC/Zen 3 IPC, it may well end up doing so with less power. Remember the Pentium M.
What I'm trying to say is, you've got a destination: IPC. These three architectures are taking different routes of power and area to get there. GC has taken a road with heavy toll fees. Zen 3, much cheaper. Gracemont appears to be on an even more economical road. The toll, even on this path, will go up but it'll still be lower than GC's. Zen, in general, is proof of that, surpassing Intel's IPC at a lower point of power.
GeoffreyA - Sunday, November 7, 2021 - link
Anyhow, this is just a generic comment by a layman who's got a passion for these things, and doesn't mean to talk as if he knows better than the engineers who built it.Wrs - Sunday, November 7, 2021 - link
It's not trivial to design a core from scratch without defining an instruction set from scratch, i.e., breaking all backward compatibility. x86 has a tremendous amount of legacy. ARM has quite a bit as well, and growing each year.Can they redo Golden Cove or Gracemont for more efficiency at same perf/more perf at same efficiency? Absolutely, nothing is perfect and there's no defined tradeoff between performance and efficiency that constitutes perfect. But simply enlarging Gracemont to near Golden Cove IPC (a la Pentium M to Conroe) is not it. By doing so you gradually sacrifice the efficiency advantage in Gracemont, and might get something worse than Golden Cove if not optimized well.
The big.LITTLE concept has proven advantages in mobile and definitely has merit with tweaks/support on desktop/server. The misconception you may have is that Golden Cove isn't an inherently inefficient core like Prescott (P4) or Bulldozer. It's just sometimes driven at high turbo/high power, making it look inefficient when that's really more a process capability than a liability.
GeoffreyA - Monday, November 8, 2021 - link
Putting together a new core doesn't necessarily mean a new ISA. It could still be x86.Certainly, Golden Cove isn't of Prescott's or Bulldozer's nature and the deplorable efficiency that results from that; but I think it's pretty clear that it's below Zen 3's perf/watt. Now, Gracemont is seemingly of Zen's calibre but at an earlier point of its history. So, if they were to scale this up slowly, while scrupously maintaining its Atom philosophy, it would reach Zen 3 at similar or less power. (If that statement seems laughable, remember that Skylake > Zen 1, and Gracemont is roughly equal to Skylake.) Zen 3 is right on Golden Cove's tail. So why couldn't Gracemont's descendant reach this class using less power? Its design is sufficiently different from Core to suggest this isn't entirely fantasy.
And the fashionable big/little does have advantages; but question is, do those outweigh the added complexity? I would venture to say, no.
mode_13h - Monday, November 8, 2021 - link
> they're still being restricted by choices made in the Pentium Pro era.No way. There's no possible way they're still beholden to any decisions made that far back. For one thing, their toolchain has probably changed at least a couple times, since then. But there's also no way they're going to carry baggage that's either not pulling its weight or is otherwise a bottleneck for *that* long. Anything that's an impediment is going to get dropped, sooner or later.
> As for the E-cores, if I'm not mistaken, they're at greater perf/watt than Skylake
Gracemont is made on a different node than Skylake. If you backported it to the original 14 nm node that was Skylake's design target, they wouldn't be as fast or efficient.
> why not scale it up a bit more, and by the time it reaches GC/Zen 3 IPC,
> it may well end up doing so with less power.
Okay, so even if you make everything bigger and it can even reach Golden Cove's IPC without requiring major parts being redesigned, it's not going to clock as high. Plus, you're going to lose some efficiency, because things like OoO structures scale nonlinearly in perf/W. And once you pipeline it and do the other things needed for it to reach Golden Cove's clock speeds, it's going to lose yet more efficiency, probably converging on what Golden Cove's perf/W.
There are ways you design for power-efficiency that are fundamentally different from designing for outright performance. You don't get a high-performance core by just scaling up an efficiency-optimized core.
GeoffreyA - Monday, November 8, 2021 - link
Well, you've stumped me on most points. Nonetheless, old choices can survive pretty long. I've got two examples. Can't find any more at present. The instruction fetch bandwidth of 16 bytes, finally doubled in Golden, goes all the way back to Pentium Pro. That could've more related to the limitations of x86 decoding, though. Then, register reads were limited to two or three per clock cycle, going back to Pentium Pro, and only fixed in Sandy Bridge. Those are small ones but it goes to show.I would say, Gracemont is different enough for it to diverge from Golden Cove in terms of perf/watt. One basic difference is that it's using a distributed scheduler design (following in the footsteps of the Athlon, Zen, and I believe the Pentium 4), compared to Pentium Pro-Golden Cove's unified scheduler. Then, it's got 17 execution ports, more than Zen 3's 14 and GC's 12. It's ROB is 256 entries, equal to Zen 3. Instruction boundaries are being marked, etc., etc. It's clock speed is lower? Well, that's all right if its IPC is higher than frequency-obsessed peers. I think descendants of this core could baffle both their elder brothers and the AMD competition.
GeoffreyA - Monday, November 8, 2021 - link
Sorry for all the it's! Curse that SwiftKey!mode_13h - Tuesday, November 9, 2021 - link
> it's got 17 execution portsThat's for simplicity, not by necessity. Most CPUs map multiple different sorts of operations per port, but Gracemont is probably designed in some way that made it cheaper for them just to have dedicated ports for each. I believe its issue bandwidth is 5 ops/cycle.
> It's clock speed is lower? Well, that's all right if its IPC is higher than frequency-obsessed peers.
It would have to be waaay higher, in order to compensate. It's not clear if that's feasible or the most efficient route to deliver that level of performance.
> I think descendants of this core could baffle both their elder brothers and the AMD competition.
In server CPUs? Quite possibly. Performance per Watt and per mm^2 (which directly correlates with perf/$) could be extremely competitive. Just don't expect it to outperform anyone's P-cores.
GeoffreyA - Wednesday, November 10, 2021 - link
I'm out of answers. I suppose we'll have to wait and see how the battle goes. In any case, what is needed is some new paradigm that changes how CPUs operate. Clearly, they're reaching the end of the road. Perhaps the answer will come from new physics. But I wouldn't be surprised there's some fundamental limit to computation. That's a thought.