The Intel 12th Gen Core i9-12900K Review: Hybrid Performance Brings Hybrid Complexity
by Dr. Ian Cutress & Andrei Frumusanu on November 4, 2021 9:00 AM ESTFundamental Windows 10 Issues: Priority and Focus
In a normal scenario the expected running of software on a computer is that all cores are equal, such that any thread can go anywhere and expect the same performance. As we’ve already discussed, the new Alder Lake design of performance cores and efficiency cores means that not everything is equal, and the system has to know where to put what workload for maximum effect.
To this end, Intel created Thread Director, which acts as the ultimate information depot for what is happening on the CPU. It knows what threads are where, what each of the cores can do, how compute heavy or memory heavy each thread is, and where all the thermal hot spots and voltages mix in. With that information, it sends data to the operating system about how the threads are operating, with suggestions of actions to perform, or which threads can be promoted/demoted in the event of something new coming in. The operating system scheduler is then the ring master, combining the Thread Director information with the information it has about the user – what software is in the foreground, what threads are tagged as low priority, and then it’s the operating system that actually orchestrates the whole process.
Intel has said that Windows 11 does all of this. The only thing Windows 10 doesn’t have is insight into the efficiency of the cores on the CPU. It assumes the efficiency is equal, but the performance differs – so instead of ‘performance vs efficiency’ cores, Windows 10 sees it more as ‘high performance vs low performance’. Intel says the net result of this will be seen only in run-to-run variation: there’s more of a chance of a thread spending some time on the low performance cores before being moved to high performance, and so anyone benchmarking multiple runs will see more variation on Windows 10 than Windows 11. But ultimately, the peak performance should be identical.
However, there are a couple of flaws.
At Intel’s Innovation event last week, we learned that the operating system will de-emphasise any workload that is not in user focus. For an office workload, or a mobile workload, this makes sense – if you’re in Excel, for example, you want Excel to be on the performance cores and those 60 chrome tabs you have open are all considered background tasks for the efficiency cores. The same with email, Netflix, or video games – what you are using there and then matters most, and everything else doesn’t really need the CPU.
However, this breaks down when it comes to more professional workflows. Intel gave an example of a content creator, exporting a video, and while that was processing going to edit some images. This puts the video export on the efficiency cores, while the image editor gets the performance cores. In my experience, the limiting factor in that scenario is the video export, not the image editor – what should take a unit of time on the P-cores now suddenly takes 2-3x on the E-cores while I’m doing something else. This extends to anyone who multi-tasks during a heavy workload, such as programmers waiting for the latest compile. Under this philosophy, the user would have to keep the important window in focus at all times. Beyond this, any software that spawns heavy compute threads in the background, without the potential for focus, would also be placed on the E-cores.
Personally, I think this is a crazy way to do things, especially on a desktop. Intel tells me there are three ways to stop this behaviour:
- Running dual monitors stops it
- Changing Windows Power Plan from Balanced to High Performance stops it
- There’s an option in the BIOS that, when enabled, means the Scroll Lock can be used to disable/park the E-cores, meaning nothing will be scheduled on them when the Scroll Lock is active.
(For those that are interested in Alder Lake confusing some DRM packages like Denuvo, #3 can also be used in that instance to play older games.)
For users that only have one window open at a time, or aren’t relying on any serious all-core time-critical workload, it won’t really affect them. But for anyone else, it’s a bit of a problem. But the problems don’t stop there, at least for Windows 10.
Knowing my luck by the time this review goes out it might be fixed, but:
Windows 10 also uses the threads in-OS priority as a guide for core scheduling. For any users that have played around with the task manager, there is an option to give a program a priority: Realtime, High, Above Normal, Normal, Below Normal, or Idle. The default is Normal. Behind the scenes this is actually a number from 0 to 31, where Normal is 8.
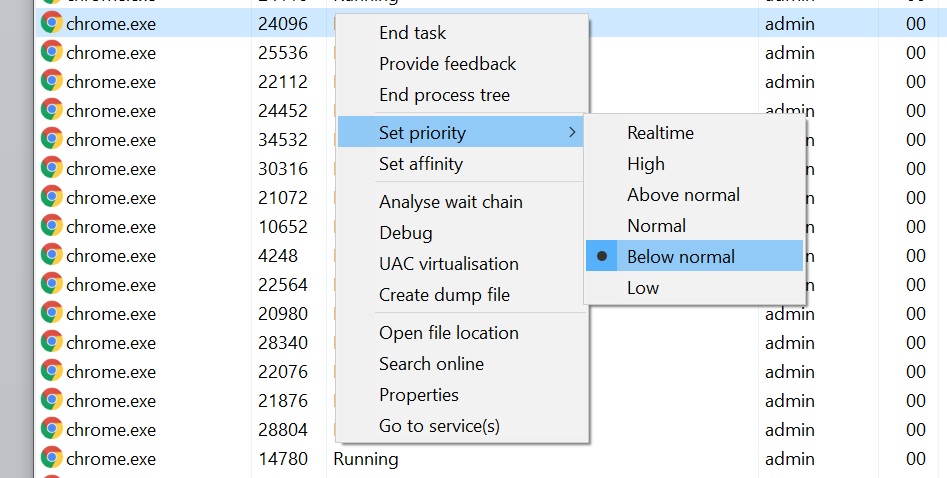
Some software will naturally give itself a lower priority, usually a 7 (below normal), as an indication to the operating system of either ‘I’m not important’ or ‘I’m a heavy workload and I want the user to still have a responsive system’. This second reason is an issue on Windows 10, as with Alder Lake it will schedule the workload on the E-cores. So even if it is a heavy workload, moving to the E-cores will slow it down, compared to simply being across all cores but at a lower priority. This is regardless of whether the program is in focus or not.
Of the normal benchmarks we run, this issue flared up mainly with the rendering tasks like CineBench, Corona, POV-Ray, but also happened with yCruncher and Keyshot (a visualization tool). In speaking to others, it appears that sometimes Chrome has a similar issue. The only way to fix these programs was to go into task manager and either (a) change the thread priority to Normal or higher, or (b) change the thread affinity to only P-cores. Software such as Project Lasso can be used to make sure that every time these programs are loaded, the priority is bumped up to normal.








474 Comments
View All Comments
bananaforscale - Friday, November 5, 2021 - link
I do wonder about the scheduler interactions if we add Process Lasso into the mix.mode_13h - Friday, November 5, 2021 - link
Ian, please publish the source to your 3D Particle Movement benchmark. Let us see what the benchmark is doing. Also, it's not only AMD that can optimize the AVX2 path. Please let the community have a go at it.mode_13h - Friday, November 5, 2021 - link
> The core also supports dual AVX-512 ports, as we’re detecting> a throughput of 2 per cycle on 512-bit add/subtracts.
I thought that was true of all Intel's AVX-512 capable CPUs? What Intel has traditionally restricted is the number of FMAs. And if you look at the AVX-512 performance of 3DPM on Rocket Lake and Alder Lake, the relative improvement is only 6%. That doesn't support the idea that Golden Cove's AVX-512 is any wider than that of Cypress Cove, which I thought was established to be single-FMA.
SystemsBuilder - Saturday, November 6, 2021 - link
Cascade lake X and Skylake X/XE core i9 and Xeons with more that 12 cores (it think) have two AVX-512 capable FMA ports (port 0 and port 5) while all other AVX-512 capable CPUs have 1 (Port 0 fused).the performance gap could be down to coding. you need to vectorize your code in such a way that you feed both ports at maximum bandwidth.
However, in practice it turns out that the bottle neck is seldom the AVX-512 FMA ports but the memory bandwidth, i.e. it is very hard to keep up with the FMAs, each capable of retiring many of the high end vector operations in 4 clock cycles. e.g. multiply two vectors of 16 32bit floats and add to a 3rd vector in 4 clock cycles. Engaging both FMAs => you retire one FMA vector op every 2 cycles. Trying to avoid getting too technical here, but with a bit of math you see that the total bandwidth capability of the FMAs easily outstrips the cache, even if most vectors are kept in the Z registers – the resisters can only absorbs so much and at the steady state, the cache/memory hierarchy becomes the bottleneck depending on the problem size.
Some clever coding can work around that and hide some of the memory reads (using prefetching etc) but again there is only so much you can do. In other words two AVX-512 FMAs are beasts!
coburn_c - Friday, November 5, 2021 - link
This hybrid design smacks of 5+3 year ago thinking when they wanted to dominate mobile. Maybe that's why it needs 200+ watts to be performant.mode_13h - Friday, November 5, 2021 - link
This doesn't make sense. Their P-cores were never suitable for phones or tablets. Still aren't.I think the one thing we can say is *not* behind Alder Lake is the desire to make a phone/tablet chip. It would be way too expensive and the P-core would burn too much power at even the lowest clockspeeds.
tygrus - Saturday, November 6, 2021 - link
It appears the mixing is more trouble than they are worth for pure mid to high range desktop use. Intel should have split the Desktop CPU's from the mobile CPU's. Put P-cores in the new mid to high range desktops. Put the E-cores in mobiles or cheap desktops/NUC.Wrs - Saturday, November 6, 2021 - link
The mixing helps with a very sought-after trait of high-end desktops. Fast single/lightly threaded performance AND high multithreaded capacity. Meaning very snappy and can handle a lot of multitasking. It is true they can pump out more P cores and get rid of E cores, but that would balloon the die size and cut yields, spiking the cost.mode_13h - Saturday, November 6, 2021 - link
> AND high multithreaded capacity.Yes. This is supported with a very simple experiment. Look at the performance delta between 8 P-Cores and the full 8 + 8 configuration, on highly-threaded benchmarks. All the 8 + 8 configuration has to do is beat the P-core -only config by 25%, in order to prove it's a win.
The reason is simple. Area-wise, the 8 E-cores are equivalent to just 2 more P-cores. The way I see it is as an easy/cheap way for Intel to boost their CPU on highly-threaded workloads. That's what sold me on it. Before I saw that, I only thought Big.Little was good for power-savings in mobile.
mode_13h - Saturday, November 6, 2021 - link
Forgot to add that page 9 shows it meets this bar (I get 25.9%), but the reason it doesn't scale even better is due to the usual reasons for sub-linear scaling. Suffice it to say that a 10 P-core wouldn't scale linearly either, meaning the net effect is almost certainly better performance in the 8+8 config (for integer, at least).