AMD Zen Architecture Roadmap: Zen 5 in 2024 With All-New Microarchitecture
by Ryan Smith on June 9, 2022 4:21 PM EST
Today is AMD’s Financial Analyst Day, the company’s semi-annual, analyst-focused gathering. While the primary purpose of the event is for AMD to reach out to investors, analysts, and others to demonstrate the performance of the company and why they should continue to invest in the company, FAD has also become AMD’s de-facto product roadmap event. After all, how can you wisely invest in AMD if you don’t know what’s coming next?
As a result, the half-day series of presentations is full of small nuggets of information about products and plans across the company. Everything here is high-level – don’t expect AMD to hand out the Zen 4 transistor floorplan – but it’s easily our best look at AMD’s product plans for the next couple of years.
Kicking off FAD 2022 with what’s always AMD’s most interesting update is the Zen architecture roadmap. The cornerstone of AMD’s recovery and resurgence into a competitive and capable player in the x86 processor space, the Zen architecture is the basis of everything from AMD’s smallest embedded CPUs to their largest enterprise chips. So what’s coming down the pipe over the next couple of years is a very big deal for AMD, and the industry as a whole.
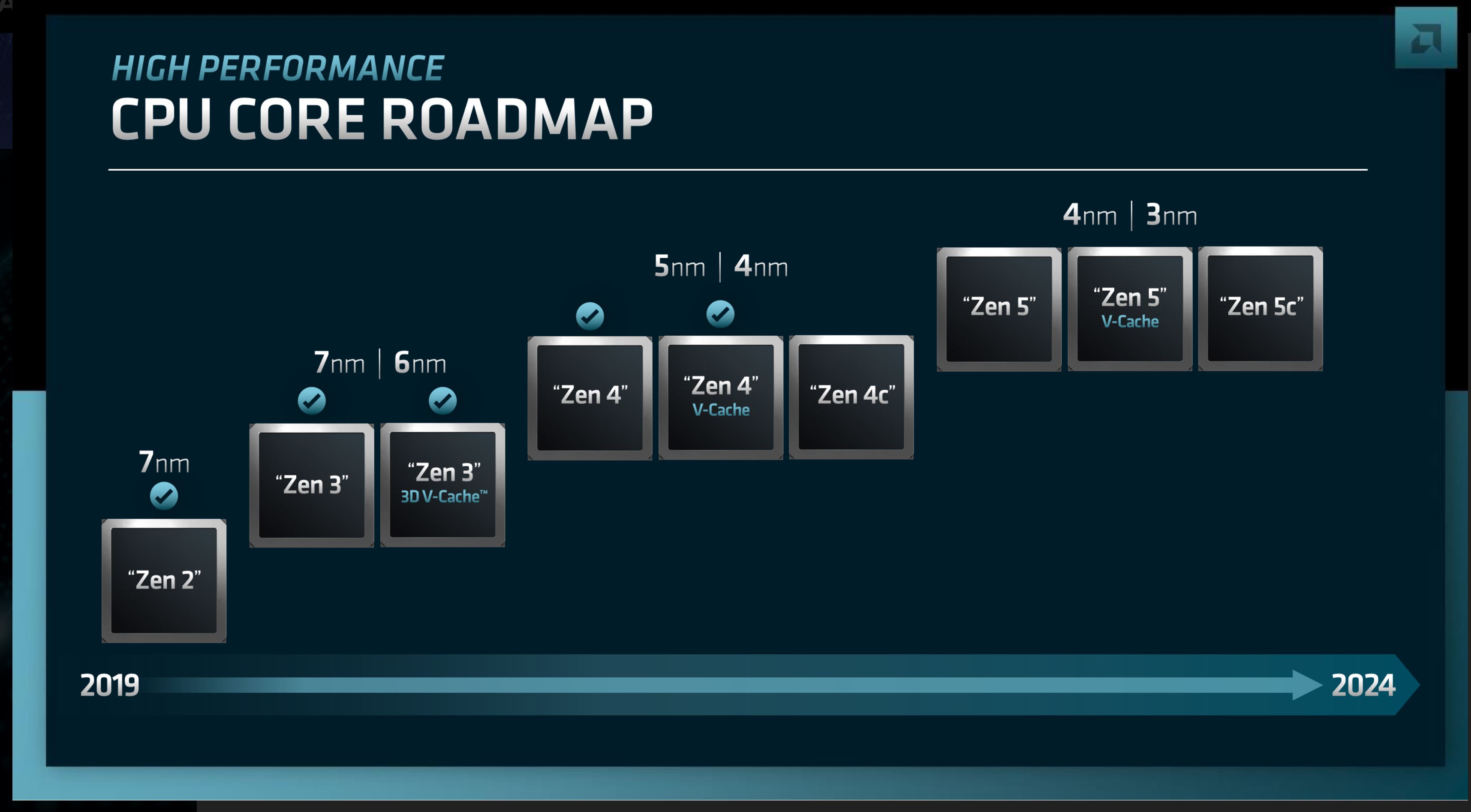
Zen 4: Improving Performance and Perf-Per-Watt, Shipping Later This Year
Diving right in, AMD is currently in the process of ramping up their Zen 4 architecture-based products. This includes the Ryzen 7000 (Raphael) client CPUs, as well as their 4th generation EPYC (Genoa) server CPUs. Both of these are due to launch later this year.

We’ve seen bits and pieces of information on Zen 4 thus far, most recently with the Ryzen 7000 announcement at Computex. Zen 4 brings new CPU core chiplets as well as a new I/O die, adding support for features such as PCI-Express 5.0 and DDR5 memory. And on the performance front, AMD is aiming for significant performance-per-watt and clockspeed improvements over their current Zen 3-based products.
Meanwhile, AMD is following up that Computex announcement by clarifying a few things. In particular, the company is addressing questions around Instruction per Clock (IPC) expectations, stating that they expect Zen 4 to offer an 8-10% IPC uplift over Zen 3. The initial Computex announcement and demo seemed to imply that most of AMD’s performance gains were from clockspeed improvements, so AMD is working to respond to that without showing too much of their hand months out from the product launches.
Coupled with that, AMD is also disclosing that they’re expecting an overall single-threaded performance gain of greater than 15% – with an emphasis on “greater than.” ST performance is a mix of IPC and clockspeeds, so at this point AMD can’t get overly specific since they haven’t locked down final clockspeeds. But as we’ve seen with their Computex demos, for lightly threaded workloads, 5.5GHz (or more) is currently on the table for Zen 4.
Finally, AMD is also confirming that there are ISA extensions for AI and AVX-512 coming for Zen 4. At this point the company isn’t clarifying whether either (or both) of those extensions will be in all Zen 4 products or just a subset – AVX-512 is a bit of a space and power hog, for example – but at a minimum, it’s reasonable to expect these to show up in Zen 4 server parts. The addition of AI instructions will help AMD keep up with Intel and other competitors in the short run, as CPU AI performance has already become a battleground for chipmakers. Though just what this does for AMD’s competitiveness there will depend in large part on just what instructions (and data types) get added.
AMD will be producing three flavors of Zen 4 products. This includes the vanilla Zen 4 core, as well as the previously-announced Zen 4c core – a compact core that is for high density servers and will be going into the 128 core EPYC Bergamo processor. AMD is also confirming for the first time that there will be V-Cache equipped Zen 4 parts as well – which although new information, does not come as a surprise given the success of AMD’s V-Cache consumer and server parts.
Interestingly, AMD is planning on using both 5nm and 4nm processes for the Zen 4 family. We already know that Ryzen 7000 and Genoa are slated to use one of TSMC’s 5nm processes, and that Zen 4c chiplets are set to be built on the HPC version of N5. So it’s not immediately clear where 4nm fits into AMD’s roadmap, though we can’t rule out that AMD is playing a bit fast and loose with terminology here, since TSMC’s 4nm processes are an offshoot of 5nm (rather than a wholly new node) and are typically classified as 5nm variants to start with.
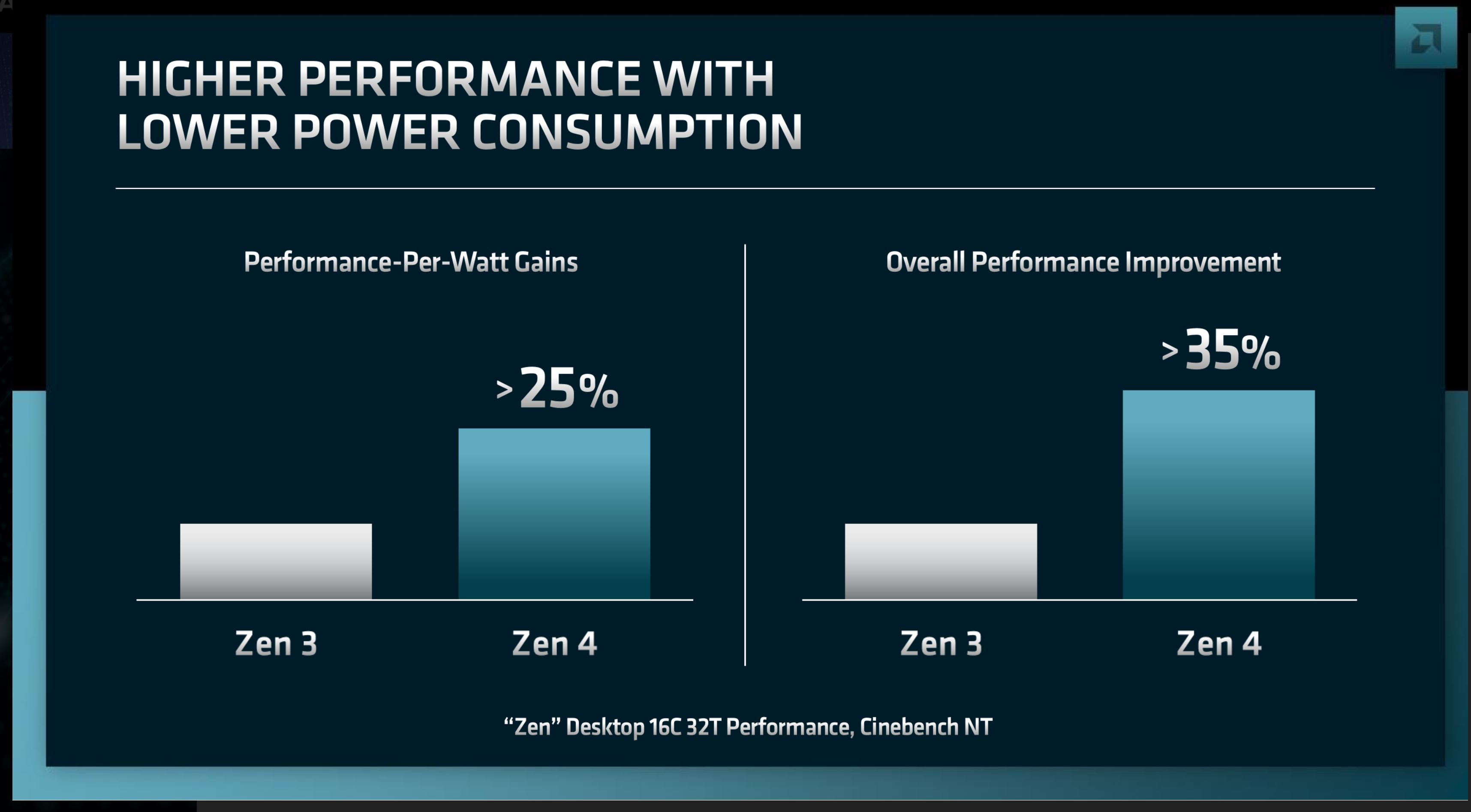
At this point, AMD is expecting to see a >25% increase in performance-per-watt with Zen 4 over Zen 3 (based on desktop 16C chips running CineBench). Meanwhile the overall performance improvement stands at >35%, no doubt taking advantage of both the greater performance of the architecture per-thread, and AMD’s previously disclosed higher TDPs (which are especially handy for uncorking more performance in MT workloads). And yes, these are terrible graphs.
Zen 5 Architecture: All-New Microarchitecture for 2024

Meanwhile, carrying AMD’s Zen architecture roadmap into 2024 is the Zen 5 architecture, which is being announced today. Given that AMD isn’t yet shipping Zen 4, their details on Zen 5 are understandably at a very high level. None the less, they also indicate that AMD won’t be resting on their laurels, and have some aggressive updates planned.
The big news here is that AMD is terming the Zen 5 architecture as an “All-new microarchitecture”. Which is to say, it’s not merely going to be an incremental improvement over Zen 4.
In practice, no major vendor designs a CPU architecture completely from scratch – there’s always going to be something good enough for reuse – but the message from AMD is clear: they’re going to be doing some significant reworking of their core CPU architecture in order to further improve their performance as well as energy efficiency.
As for what AMD will disclose for right now, Zen 5 will be re-pipelining the front end and once again increasing their issue width. The devil is in the details here, but coming from Zen 3 and its 4 instruction/cycle decode rate, it’s easy to see why AMD would want to focus on that next – especially when on the backend, the integer units already have a 10-wide issue width.
Meanwhile, on top of Zen 4’s new AI instructions, Zen 5 is integrating further AI and machine learning optimizations. AMD isn’t saying much else here, but they have a significant library of tools to pick from, covering everything from AI-focused instructions to adding support for even more data types.
AMD expects the Zen 5 chip stack to be similar to Zen 4 – which is to say that they’re going to have the same trio of designs: a vanilla Zen 5 core, a compact core (Zen 5c), and a V-Cache enabled core. For AMD’s customers this kind of continuity is very important, as it gives customers a guarantee that AMD’s more bespoke configurations (Zen 4c & V-Cache) will have successors in the 2024+ timeframe. From a technical perspective none of this is too surprising, but from a business standpoint, customers want to make sure they aren’t adopting dead-end hardware.

Finally, AMD has an interesting manufacturing mix planned for Zen 5. Zen 5 CPU cores will be fabbed on a mix of 4nm and 3nm processes, which unlike the 5nm/4nm mix for Zen 4, TSMC’s 4nm and 3nm nodes are very different. 4nm is an optimized version of 5nm, whereas 3nm is a whole new node. So if AMD’s manufacturing plans move ahead as currently laid out, Zen 5 will be straddling a major node jump. That said, it’s not unreasonable to suspect that AMD is hedging their bets here and leaving 4nm on the table in case 3nm isn’t as far along as they’d like.
Wrapping things up, the Zen 5 architecture is slated for 2024. AMD isn’t giving any further information on when in the year that might be, though looking at Zen 3 and Zen 4, both of those were/will be released later on in 2020 and 2022 respectively. So H2/EOY 2024 is as good as guess as any.








156 Comments
View All Comments
schujj07 - Sunday, June 12, 2022 - link
Zen 4 Epyc has even more bandwidth as it will have 12 channel DDR5.OreoCookie - Wednesday, June 15, 2022 - link
“Not at all. It's only workstation-class.”Anandtech tested memory bandwidth of two Milan EPYC 7000-series processors, i. e. AMD's server processors, and they were tested at 103~113 GB/s peak throughput (https://www.anandtech.com/show/16529/amd-epyc-mila... Your figures are the theoretical max bandwidth. To be fair, I could not find figures for tested bandwidth for the plain M1. On the other hand, to be fair, we are comparing Apple's second-gen lowest end chips meant for its entry-level notebooks and desktops to AMD's current-gen highest-performing chips. Extrapolating from the the numbers of the M1 Max, the M1 Ultra should have about twice the sustained throughput due to the CPU complex only than AMD's current top-of-the-line server CPUs.
“So, Apple is really only barely keeping pace, considering graphics needs a share of that bandwidth. For perspective, the PS4 that launched almost 9 years ago had 176 GB/s unified memory bandwidth.”
Barely keeping pace? Apple's highest-end SoC has a theoretical max memory bandwidth of 800 GB/s, which is comparable with a current top-of-the-line graphics card like nVidia's RTX 3080 (about 912 GB/s).
And why don't we look at the PS5 instead of the PS4? The PS5 has a theoretical max memory throughput of 448 GB/s, roughly on par with the M1 Max. So is Apple really behind? Doesn't look like it to me. Especially once you include efficiency in your considerations.
mode_13h - Wednesday, June 15, 2022 - link
> Anandtech tested memory bandwidth of two Milan EPYC 7000-series processors,> i. e. AMD's server processors, and they were tested at 103~113 GB/s peak throughput
So, you're comparing Apple's theoretical bandwidth to AMD's actual bandwidth? Nice. Try again.
Also, to interpret benchmarks, you need to know what you're looking at. The Stream Triad benchmark is meant to stress the cache subsystem. It assigns each thread to do a series of 2 reads + 1 write. In copy-back caches, the write actually generates an extra read. There are ways around this, but the benchmark is written in a naive fashion.
So, to achieve 113.1 GB/s on that benchmark, the underlying memory system is actually doing 150.8 GB/s. As mentioned in the article, Altra has a hardware optimization which detects the memory access pattern and eliminates the extra read. That's the main reason it's able to achieve 174.4 GB/s, using the same 8x DDR4-3200 memory configuration as the Epyc. Also, the Epyc is being run in the generally slower NPS1 topology, meaning traffic is crossing all of the NUMA sub-domains.
Now, as for the rest of the margin, you seem to have fallen in the trap of citing the launch review of Milan, which used a pre-production platform. Unfortunately, they didn't rerun the Stream.Triad benchmark for the updated benchmarks, but if you compare the SPECint results, multithreaded performance between the two articles jumped by 7.9%. It's hard to say what difference there'd have been in memory performance, but we can use that to get a rough idea.
https://www.anandtech.com/show/16778/amd-epyc-mila...
> Barely keeping pace?
Yes, because Intel mainstream desktop CPUs have a nominal bandwidth almost as high. Everyone gets a boost, moving to DDR5. They are not special. 100 vs. 76.8 is significant, but not the massive difference you tried to paint.
> Apple's highest-end SoC ...
Uh oh. Now you go and change the subject. Irrelevant.
This article is about the M2 and I was simply putting it into perspective. I take it you're offended by this or what it reveals, because otherwise I don't see why you'd drag completely different Apple chips into the discussion. Seems like a face-saving move, but ultimately just makes you look desperate.
mode_13h - Wednesday, June 15, 2022 - link
And BTW, I'm even going to retract what I said about "workstation bandwidth", because a quad-channel DDR5 setup is going to spec out north of 150 GB/s. So, if we're comparing like-for-like, rather than against old DDR4-based products about to be replaced, then it doesn't even reach the workstation tier.lemurbutton - Friday, June 10, 2022 - link
Apple is winning the premium laptop market and is growing significantly faster than x86 laptop makers. In a few years, Mac marketshare will look very different.GeoffreyA - Friday, June 10, 2022 - link
So, Apple and their fearsome M have destroyed both AMD and Intel. The tide has turned. Dear friends, who knew this day would come so swiftly? The only thing we can do now is take all our x86 computers and, with a sigh, throw them in the bin as fast as we can because they're useless now.schujj07 - Friday, June 10, 2022 - link
Inside of the MAC universe the M series is king. However, what happens when it has to run on an OS that isn't highly tuned like OSX or software that doesn't have the fine tuning? Probably the same thing that happens to every ARM uArch, it bogs down to 2015 x86 performance level.web2dot0 - Saturday, June 11, 2022 - link
You can't prove a negative buddy. Where did you learn to reason?No amount of tuning can you get away with a 400GB/s memory bandwidth DDR5, ANE, and Media Engines.
Performance per watt is undisputed.
If you are gonna criticize Apple, pick something more tangible than a bunch of hypotheticals.
Oxford Guy - Saturday, June 11, 2022 - link
Sally: '8 - 5 = 3.'Amy: 'Sally, you're silly. Everyone knows you can't prove a negative!'
Oxford Guy - Saturday, June 11, 2022 - link
Stripping away features isn't 'fine tuning'.Look at the disaster that is the Music program, created by Apple to replace iTunes — without users having any choice.