SSD versus Enterprise SAS and SATA disks
by Johan De Gelas on March 20, 2009 2:00 AM EST- Posted in
- IT Computing
RAID 5 in Action
RAID 0 is good way to see how adding more disks scales up your writing and reading performance. However, it is rarely if ever used for any serious application. What happens if we use RAID 5?
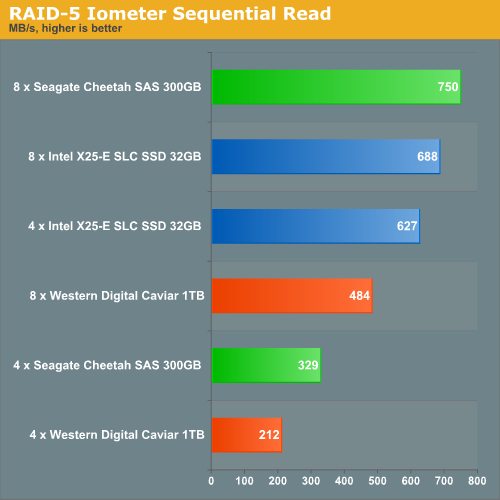
We see a picture very similar to what we saw with our RAID 0 numbers. The SAS protocol is more efficient than the SATA interface. Four SLC SSDs already come close to the highest bandwidth that our Adaptec HBA is capable of extracting out of SATA disks. Add four more and you bump into a 700 MB/s bottleneck. At first, our eight drive results look weird, as they are more than twice as fast as the four drives results. In the case of four drives, our controller will write three striped blocks of data and one parity block on our RAID array. With eight drives, we are striping seven blocks and we only have to write one parity block. So we can expect a maximum scaling of 2.3 (7/3), which explains the "the better than doubling" in performance.
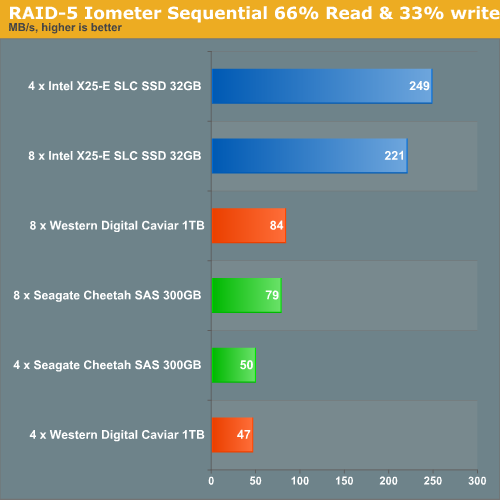
Once we interleave some writing with reading, something remarkable happens: eight SLC SSDS are (slightly) slower than four are. We have no real explanation for this, other than that this might have something to do with the choices Adaptec made when writing the firmware. We tried out the Areca 1680 controller, which uses the same controller (Intel Dual-core IOP348 1.2GHz) but with different firmware.
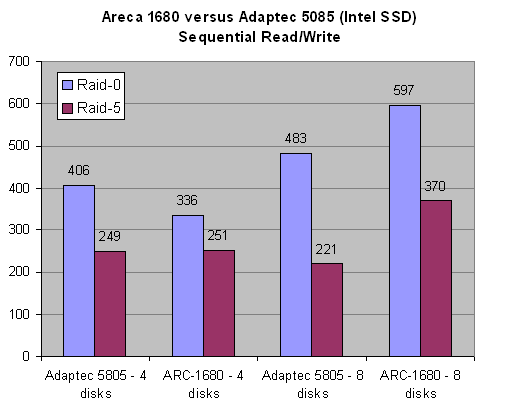
The Areca 1680 controller is almost 20% slower with four SLC SSD drives in RAID 0, but scales well from four to eight drives (+78%). In comparison, the Adaptec controller is only 19% faster with an additional four drives. In RAID 5 the difference is even more dramatic. Adding four extra drives (for a total of eight) leads to a performance decrease on the Adaptec card, while there is a decent 47% scale up in performance in the same situation on the Areca 1680. Thus, we conclude that is likely that the Adaptec firmware is to blame. We used both the 1.44 (August 2008) and 1.46 (February 2009) firmware, and although the latest firmware gave a small boost, we made the same observations.








67 Comments
View All Comments
JohanAnandtech - Friday, March 20, 2009 - link
Ok, good feedback. On monday, I'll check the exact length of the test (it is several minutes), and we do have a follow up which shows you quite a bit of what is happening. Disk queue lengths are quite high, so that should tell you also that it is not just a "fill cache", "dump cache" thing. We did see this behavior with small databases though (2 GB etc.)Just give me a bit of time, After the Nehalem review, I'll explore these kind of things. We also noticed that the deadline scheduler is the best for the SAS disks, but noop for the SSD. I'll explore the more in depth stuff in a later article.
JarredWalton - Friday, March 20, 2009 - link
As stated in several areas in the article, SSDs clearly don't make sense if you need a large database - which is why Google as an example wouldn't consider them at present. The current size requirements are quite reasonable (less than 512GB if you use 8x64GB SSDs... and of course you can bump that up to 16x64GB if necessary, though you'd have to run more SATA cards, use software RAID, or some other changes), but there will certainly be businesses that need more storage.However, keep in mind that some companies will buy larger SCSI/SAS drives and then partition/format them as a smaller drive in order to improve performance - i.e. if you only use 32GB on a 300GB disk, the seek times will improve because you only need to seek over a smaller portion of the platters - and transfer rates will improve because all of the data will be on the outer sectors.
At one point I worked for a corporation that purchased the then top-of-the-line 15k 32GB disks and they were all formatted to 8GB. We had a heavily taxed database - hundreds of concurrent users working in a warehouse, plus corporate accesses and backups - but the total size of the database was small enough that we didn't need tons of storage. Interestingly enough, we ran the database on an EMC box that probably cost close to $1 million (using IBM POWER5 or POWER6 servers that added another couple million I think). I wonder if they have looked at switching to SSDs instead of SCSI/SAS now? Probably not - they'll just do whatever IBM tells them they should do!
virtualgeek - Friday, March 20, 2009 - link
The key is that as a general statement:Lowest capital cost optimization happen at the application tier (query optimization),
Next lowest capital cost optimization happens at the database tier (proper up-front DB design)
Next lowest capital cost optimization happens by adding RAM to the database tier.
Next lowest capital cost optimization happens by adding database server horsepower or storage performance (depending on what is the gate to performance).
But - in various cases, sometimes the last option is the only one (for lots of reasons - legacy app, database structure is extremely difficult to change, etc).
icrf - Friday, March 20, 2009 - link
"Capital cost" is a bit of a misnomer. It tends to be far cheaper to buy some memory than pay a DBA to tune queries.Dudler - Friday, March 20, 2009 - link
Hi,Thx for the article,
1. But your cost comparison is only valid until you have to buy new disks. Would be interesting to have an assumption on how long the SSD's would survive i a server environment, since they would be written to a lot. Even with all the wear levelling algorithms their lifespan may be short. Would the SAS disks live longer?
2. How did you test the write speed/latency? In the great article by Anand it was pretty clear that the performance of SSD's started to degrade when they got full and they wrote many small blocks. Did you simulate a "used" drive or only "fresh secure erase" it beforehand?
JarredWalton - Friday, March 20, 2009 - link
Intel states a higher MTBF for their SSD than for any conventional HDD. We have no real way of determining how long they will truly last, but Intel suggests they will last for five years running 24/7 doing constant 67% read/33% write operations. Check back in five years and we'll let you know how they're doing. ;-)As for the degraded performance testing, remember that Anand's article showed the X25 was the least prone to degraded performance, and the X25-E is designed to be even better than the X25-M. Anand http://www.anandtech.com/storage/showdoc.aspx?i=35...">didn't test new performance of the X25-E, but even in the degraded state it was still faster than any other SSD with the exception of the X25-M in its "new" state. Given the nature of the testing, I would assume that the drives are at least partially (and more likely fully) degraded in Johan's benchmarks - I can't imagine he spent the time to secure erase all the SSDs before each set of benchmarks, but I could be wrong.
IntelUser2000 - Sunday, March 22, 2009 - link
Unfortunately, I'd have to agree with mikeblas even for X25-E.Here look at this site: http://www.mysqlperformanceblog.com/2009/03/02/ssd...">http://www.mysqlperformanceblog.com/200...e-cache-...
The point in that article is that the SSD can outperform similarly priced RAID 10 setup by 5x, but due to data loss risks they have to turn off the write cache which degrades the X25-Es performance to 1/5x and ends up in the same level.
JohanAnandtech - Monday, March 23, 2009 - link
We will look into this, but the problem does not seem to occur with the ext3 filesystem. Could this be something XFS specific?It is suggested here that this is the case:
http://ondrejcertik.blogspot.com/2008/02/xfs-is-20...">http://ondrejcertik.blogspot.com/2008/02/xfs-is-20...
We'll investigate the issue.
That is good feedback, but just like reviewers should be cautious to jump to conclusions, readers should too. The blog test was quick as the blogger admits, this does not mean that the X25-E is not reliable. Also notice that he notes that he should also test with a BBU enabled RAID-card, something we did.
IntelUser2000 - Monday, March 23, 2009 - link
Thanks for the reply. While I'm not an expert on the settings for servers, they do have a point.Intel's IOP results are done with write cache on. Several webpages and posts have said they turn off write caches to prevent data loss.
And I have X25-M using Windows XP. On a simple Crystaldiskmark, my random write 4K result goes from 35MB/s to 4MB/s when the write cache setting is disabled on disk settings. Of course I have NO reason to turn write caching off.
It's something not to be ignored. If this is true the X25-E is really only suitable for extreme enthusiast PC than servers as Intel claims.
JarredWalton - Monday, March 23, 2009 - link
No enterprise setup I've ever encountered runs without a hefty backup power system, so I don't think it's as critical a problem as some suggest. If power fails and the UPS doesn't kick in to help out, you're in a world of hurt regardless.That said, there was one time where one of the facility operations team did some "Emergency Power Off" testing at my old job. Unfortunately, they didn't put the system into test mode correctly, so when they hit the switch to "test" the system, the whole building went dark!
LOL. You never saw the poop hit the fan so hard! My boss was getting reamed for letting anyone other than the computer people into the datacenter; meanwhile we're trying to get everything back up and running, and the GM of the warehouse is wondering how this all happened.
That last one is easy to answer: your senior FacOps guy somehow forgot to put the warehouse into test mode. That's hard to do since it's listed as the second or third step in the test procedures. Not surprisingly, he was in a hurry because the testing was supposed to be done two weeks earlier and somehow slipped through the cracks. Needless to say, FacOps no longer got to hold the key that would allow them to "test" that particular item.
Bottom line, though, is that in almost four years of working at that job, that was the only time where we lost power to the datacenter unexpectedly. Since we were running an EMC box for storage, we also would have had their "super capacitor" to allow the cache to be flushed to flash, resulting in no data loss.