NVIDIA’s Maximus Technology: Quadro + Tesla, Launching Today
by Ryan Smith on November 14, 2011 9:00 AM ESTNVIDIA’s Maximus Technology – Quadro + Tesla, Launching Today
Back at SIGGRAPH 2011 NVIDIA announced Project Maximus, an interesting technology initiative to allow customers to combine Tesla and Quadro products together in a single workstation and to use their respective strengths. At the time NVIDIA didn’t have a launch date to announce, but as this is a software technology rather than a hardware product, the assumption has always been that it would be a quick turnaround. And a quick turnaround it has been: just over 3 months later NVIDIA is officially launching Project Maximus as NVIDIA Maximus Technology.

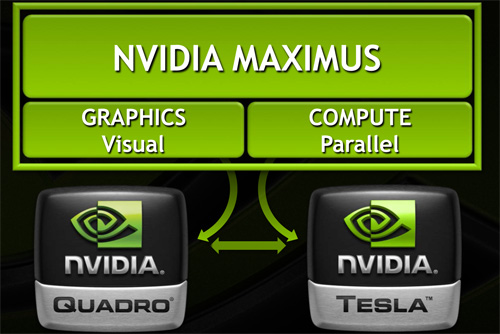
So what is Maximus Technology? As NVIDIA likes to reiterate to their customers it’s not a new product, it’s a new technology – a new way to use NVIDIA’s existing Quadro and Tesla products together. There’s no new hardware involved, just new features in NVIDIAs drivers and new hooks exposed to application developers. Or put more succinctly, in the same vein that Optimus was a driver technology to allow the transparent combination of NVIDIA mobile GPUs with Intel IGPs, Maximus is a driver technology to allow the transparent combination of NVIDIA’s Quadro and Tesla products.
With Maximus NVIDIA is seeking to do a few different things, all of which come back to a single concept: utilizing Quadro and Tesla cards together at the tasks they’re best suited at. This means using Quadro cards for graphical tasks while using Tesla for compute tasks where direct graphical rendering isn’t necessary. Ultimately this seems like an odd concept at first – high end Quadros are fully compute capable too – but it’s something that makes more sense once we look at the current technical limitations of NVIDIA’s hardware, and what use cases they’re proposing.
Combining Quadro & Tesla: The Technical Details
The fundamental base of Maximus is NVIDIA’s drivers. For Maximus NVIDIA needed to bring Quadro and Tesla together under a single driver, as they previously used separate drivers. NVIDIA has used a shared code base for many years now, so Tesla and Quadro (and GeForce) were both forks of the same drivers, but those forks needed to be brought together. This is harder than it sounds as while Quadro drivers are rather straightforward – graphical rendering without all the performance shortcuts and with support for more esoteric features like external synchronization sources – Tesla has a number of unique optimizations, primarily the Tesla Compute Cluster driver, which moved Tesla out from under Windows’ control as a graphical device.
The issue with the forks had to be resolved, and the result was that NVIDIA was finally able to merge the codebase back into a single Quadro/Tesla driver as of July with the 275.xx driver series.
But this isn’t just about combining driver codebases. Making Tesla and Quadro work in a single workstation resolves the hardware issues but it leaves the software side untouched. For some time now CUDA developers have been able to select what device to send a compute task to in a system with multiple CUDA devices, but this is by definition an extra development step. Developers had to work in support for multiple CUDA devices, and in most cases needed to expose controls to the user so that users could make the final allocations. This works well enough in the hands of knowledgeable users, but NVIDIA’s CUDA strategy has always been about pushing CUDA farther and deeper in the world in order to make it more ubiquitous, and this means it always needs to become easier to use.
This brings us back to Optimus. With Optimus NVIDIA’s goal was to replace manual GPU muxing with a fully transparent system so that users never needed to take any extra steps to use a mobile GeForce GPU alongside Intel’s IGPs, or for that matter concern themselves with what GPU was being used. Optimus would – and did – take care of it all by sending lightweight workloads to the IGP while games and certain other significant workloads were sent to the NVIDIA GPU.
Maximus embodies a concept very similar to this, except with Maximus it’s about transparently allocating compute workloads to the appropriate GPU. With a unified driver base for Tesla and Quadro, NVIDIA’s drivers can present both devices to an application as usable CUDA devices. Maximus takes this to its logical conclusion by taking the initiative to direct compute workloads to the Tesla device; CUDA device allocation becomes a transparent operation to users and developers alike, just like GPU muxing under Optimus. Workloads can of course still be manually controlled, but at the end of the day NVIDIA wants developers to sit back and do nothing, and leave device allocation up to NVIDIA.
As with Optimus, NVIDIA’s desires here are rather straightforward: the harder something is to use, the slower the adoption. Optimus made it easier to get NVIDIA GPUs in laptops, and Maximus will make it easier to get CUDA adopted by more programs. Requiring developers to do any extra work to use CUDA is just one more thing that can go wrong and keep CUDA from being implemented, which in turn removes a reason for hardware buyers to purchase a high-end NVIDIA product.








29 Comments
View All Comments
Lonbjerg - Monday, November 14, 2011 - link
When other OS have a market penetration that makes for a viable profit, I am sure NVIDIA will look at them.But until then...you get what you pay for.
Filiprino - Monday, November 14, 2011 - link
LOL. GNU/Linux is the most used OS on supercomputers. You get what you pay for.Solidstate89 - Monday, November 14, 2011 - link
And?What does Optimus or Maximus have to do with large Super Computers? You don't need a graphical output for Super Computers, and last I checked a laptop with switchable graphics sure as hell isn't remotely comparable to a Super Computer.
Filiprino - Thursday, November 17, 2011 - link
But you as a worker don't have always access to your rendering farms, supercomputers or workstations. Having a laptop to program on the go is a must for increased productivity.Ryan Smith - Monday, November 14, 2011 - link
On the compute side of things I'd say NVIDIA already has strong support for Linux. Tesla is well supported, as Linux is the natural OS to pair them up with for a compute cluster.As for Optimus or improved Quadro support, realistically I wouldn't hold my breath. It's still a very small market; if NVIDIA was going to chase it, I'd expect they'd have done so by now.
iwod - Monday, November 14, 2011 - link
Hopefully all these technology lays the ground work for next generation GPU based on 28nm.We have been stuck with the current generation for too long... i think.
beginner99 - Monday, November 14, 2011 - link
Since this is artifical, is it possible to turn a 580 into a tesla and quadro? bascially getting the same performance for a lot less?Stuka87 - Monday, November 14, 2011 - link
A GTX580 and a Fermi based Quadro may share a lot in common, they are not the same thing. There are many differences between them.I seriously doubt you could make a single 580 act as both, much less one or the other.
jecs - Monday, November 14, 2011 - link
I am an artist working on CG and this is what I know.There is one software I know that can take advantage of both, Quadro's and GeForce's cards at their full potential and that is the Octane render. And as Ryan Smith explain there are software designed to use 2 graphic cards for different purposes and this rendering engine is optimized to use let's say a basic Nvidia Quadro for display or for the viewport, and a set of one or more 580-590 or any GeForce for rendering. This is great for your economy but Octane is a particular solution and not something Nvidia is pushing directly. The engineers at Refractive Software are the ones responsible to support the implementation and Nvidia could do any change at anytime that can disrupt any functionality without any compromise.
With Maximus I can see Nvidia is heading in the same direction but endorsing Tesla as the workforce. The problem for smaller studios and professionals on their own is that Tesla cards are still in the 2K level whether a GeForce's is in the $200-700.
So Maximus is a welcome as even high end studios are asking for these features that are cost effective and Nvidia is responding to their needs but Maximus is still to expensive for students or smaller studios working on CG.
Well, Nvidia may not be willing yet to give you a "cheap" card to do high end work on it as they spend a lot on R&D on their drivers, lets be fair. So ask either to your favorite software producer to implement and fully support commercial gaming cards as an alternate hardware for rendering or compute but I can guess they wont be willing to support mayor features and develop and support their own drivers.
erple2 - Wednesday, November 16, 2011 - link
Just how much money is your time worth? How many "wasted" hours of your time waiting for a render to finish adds up to 1800-1300 dollar price difference?This is an argument that I've had with several customers that seem to not quite fully realize that time wasted for things to finish working (on the CPU, GPU, RAM, Disk etc) side is time that your Engineer or Developer is very expensively twiddling their thumbs. It gets even more crazy when you realize that everyone downstream is also twiddling their thumbs waiting for work to finish.
I wonder if it's a holdover from the old "bucket" style of accounting - having separate buckets for Hardware vs. Software vs. Engineering vs. etc. It's ultimately all the same bucket for a given project - saving $15,000 on hardware costs means that your development staff (and therefore everyone else that does work after Development) is delayed hours each week just to wait for things to finish working. So while the Hardware Bucket looks great ("We saved $15,000!"), your Development bucket winds up looking terrible ("We're now $35,000 behind schedule just from development, so everything downstream is in backlog").
The flip side of that is that you can work on more projects over the long haul if you reduce "machine" time - more projects means more money (or accomplishments) which is good for the future.