NVIDIA Releases CUDA 4.1: CUDA Goes LLVM and Open Source (Kind Of)
by Ryan Smith on December 14, 2011 1:21 PM ESTSince starting their GPU Technology Conference in 2010, NVIDIA has expanded into several events so that they can hold events in Europe and Asia. The next flagship GTC will be in San Jose in May, but NVIDIA’s #2 conference, GTC Asia, is occurring this week in Beijing. As with GTC America, GTC Asia serves several purposes for the company: a research symposium, a developer training program, and of course a platform for NVIDIA to announce new GPU computing products and initiatives.
The latter is the spotlight today, as NVIDIA is using GTC Asia to announce the latest versions of their development toolkits. Parallel Nsight, NVIDIA’s Visual Studio development toolkit, has just had its second release candidate for version 2.1 released. Meanwhile (and more importantly), CUDA 4.1 is also being released as a release candidate.
CUDA version numbering is based on features so don’t let the .1 numbering undersell CUDA, CUDA 4.1 is a major release for NVIDIA due to what NVIDIA’s been doing to the backend. Previously the CUDA compiler toolchain was developed entirely within NVIDIA as a proprietary product; developers could write tools that could generate PTX code (NVIDIA’s intermediate virtual ISA), but the compiling of PTX to binary code was handled by NVIDIA’s tools. CUDA 4.1 changes this in a big way: the CUDA compiler is now being built against LLVM, the modular compiler.
LLVM in the strictest sense isn’t a true compiler (it doesn’t generate binary code on its own), but as a modular compiler it’s earned quite a reputation for generating efficient intermediate code and for being easy to add new support for new languages and architectures to. If you can generate code that goes into LLVM, then you can get out code for any architecture LLVM supports and it will probably be pretty efficient too. LLVM has been around for quite some time – and is most famously used as the compiler for Mac OS X and iOS starting with Mac OS X 10.6 – but this is the first time it’s been used for a GPU in this fashion.
So why is CUDA's using LLVM a big deal? If nothing else it should result in shorter compile times and slightly faster performing code for CUDA developers. How much any individual developer will benefit remains to be seen, but from what we’ve been hearing the compile times are anywhere between 10% to 50% quicker. Meanwhile the nature of GPU computing means that application/kernel performance won’t improve nearly as much – LLVM can’t parallelize your code for you – but it should be able to generate slightly smarter code, particularly code from non-NVIDIA languages where developers haven’t been able to invest as much time in optimizing their PTX code generation.
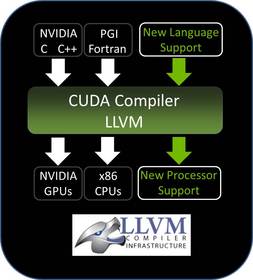
However the move to LLVM isn’t just about immediate performance benefits, it also marks the start of a longer transition by NVIDIA. As we mentioned previously LLVM is a modular compiler and was designed that way so that developers could easily add support for new languages (what goes in to LLVM) and architectures (what goes out of LLVM) to the LLVM ecosystem. In NVIDIA’s case moving to LLVM not only allows them to open up GPU computing to additional developers by making it possible to support more languages, but it allows CUDA developers to build CUDA applications for more architectures than just NVIDIA’s GPUs. Currently it’s possible to compile CUDA down to x86 through The Portland Group’s proprietary x86 CUDA compiler, and the move to LLVM would allow NVIDIA to target not just x86, but ARM too. ARM in fact is more than likely the key to all of this – just as how developers want to be able to use CUDA on their x86 + NVGPU clusters, they will want to be able to use CUDA on their Denver (ARM) + NVGPU clusters, and LLVM is how NVIDIA is going to accomplish this.
Finally, with the move to LLVM NVIDIA is also opening up CUDA, if ever so slightly. On a technical level NVIDIA’s CUDA LLVM compiler is a closed fork of LLVM (allowed via LLVM’s BSD-type license), and due to the changes NVIDIA has made it’s not possible to blindly plug in languages and architectures to the compiler. To actually add languages and architectures to CUDA LLVM you need the source code to it, and that’s where CUDA is becoming “open.” NVIDIA will not be releasing CUDA LLVM in a truly open source manner, but they will be releasing the source in a manner akin to Microsoft’s “shared source” initiative – eligible researchers and developers will be able to apply to NVIDIA for access to the source code. This allows NVIDIA to share CUDA LLVM with the necessary parties to expand its functionality without sharing it with everyone and having the inner workings of the Fermi code generator exposed, or having someone (i.e. AMD) add support for a new architecture and hurt NVIDIA’s hardware business in the process.
Source: NVIDIA Press Center








12 Comments
View All Comments
fashionbook - Tuesday, December 20, 2011 - link
Our Website: ===== www fashion-long-4biz com ====Our main product list is as follows:
smurali - Thursday, February 23, 2012 - link
I feel that NVidia is trying to add CUDA support for Clang, and generate LLVM IR for the CUDA Code. Now, that the IR is generated, they add support to LLVM and interpret the new IR generated for the CUDA source, and output the machine code for specific target architecture (GPUs). It may seem complicated, but is definitely easier than using GCC.The ultimate aim might not be just improved compilation time for applications, but also to lessen the developers' work to extend support for newer targets.