Westmere-EP to Sandy Bridge-EP: The Scientist Potential Upgrade
by Ian Cutress on March 4, 2013 9:30 AM EST- Posted in
- CPUs
- Xeon
- Westmere-EP
- Sandy Bridge-EP
Earlier this year I wrote a review of a dual processor Sandy Bridge-EP system from the point of view of the non-CS trained coder in a research group, and whether the limited knowledge of advanced processor commands (beyond basic C++ with OpenMP) was a hindrance to dual processor systems on some simple grid solvers/Brownian motion simulation. As part of the feedback to the review, I was asked by several readers using the older Westmere-EP platform doing similar types of calculations if it was worth pushing their research budget for a move from Westmere-EP to high-end Sandy Bridge-E, and whether the jump in cores/IPC would cost effective in those simulation scenarios. Thankfully Gigabyte was on hand to supply their GA-7TESM DP socket 1366 Xeon board and a pair of X5690s in order to run the comparison.

Comparing Westmere-EP to Sandy Bridge-EP
Johan’s words say it best, from his article on the E5-2600 in March 2012:
Compared to its predecessor, the Xeon X5600, the Xeon E5-2600 offers a number of improvements:
A completely improved core, as described here in Anand's article. For example, the µop cache lowers the pressure on the decoding stages and lowers power consumption, killing two birds with one stone. Other core improvements include an improved branch prediction unit and a more efficient Out-of-Order backend with larger buffers.
A vastly improved Turbo 2.0. The CPU can briefly go beyond the TDP limits, and when returning to the TDP limit, the CPU can sustain higher "steady-state" clockspeed. According to Intel, enabling turbo allows the Xeon E5 to perform 14% better in the SAP S&D 2 tier test. This compares well with the Turbo inside the Xeon 5600 which could only boost performance by 4% in the SAP benchmark.
Support for AVX Instructions combined with doubling the load bandwidth should allow the Xeon to double the peak floating point performance compared to the Xeon "Westmere" 5600.
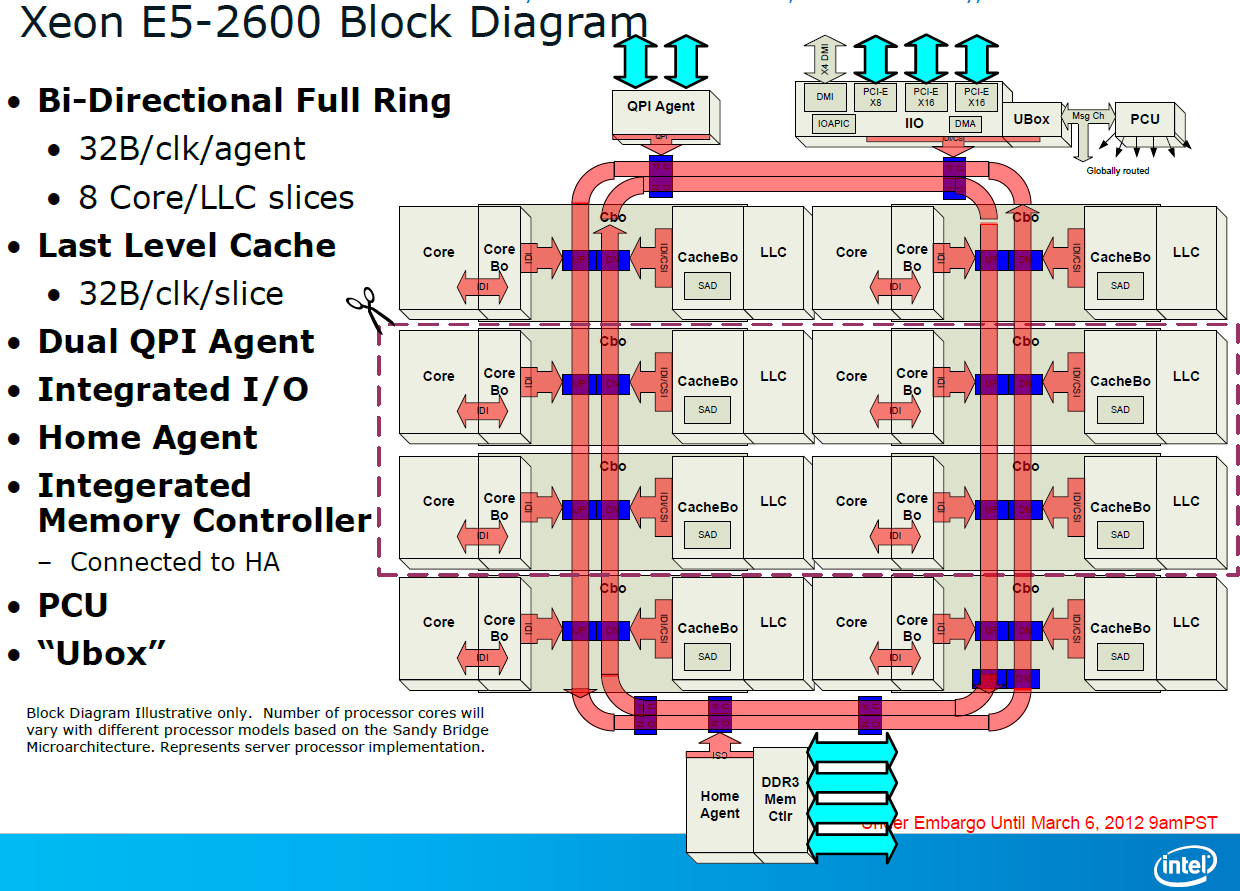
A bi-directional 32 byte ring interconnect that connects the 8 cores, the L3-cache, the QPI agent and the integrated memory controller. The ring replaces the individual wires from each core to the L3-cache. One of the advantages is that the wiring to the L3-cache can be simplified and it is easier to make the bandwidth scale with the number of cores. The disadvantage is that the latency is variable: it depends on how many hops a certain piece of data inside the L3-cache must cross before ends up at the right core.
A faster QPI: revision 1.1, which delivers up to 8 GT/s instead of 6.4 GT/s (Westmere).
Lower latency to PCI-e devices. Intel integrated a PCIe 3.0 I/O subsystem inside the die which sits on the same bi-directional 32 bit ring as the cores. PCIe 3.0 runs at 8 GT/s (PCIe 2.0: 5 GT/s), but the encoding has less overhead. As a result, PCIe 3.0 can deliver up to 1 GB full duplex per second per lane, which is twice as much as PCIe 2.0.
Removing the I/O lowered PCIe latency by 25% on average according to Intel. If you only access the local memory, Intel measured 32% lower read latency.
The access latency to PCIe I/O devices is not only significantly lower, but Intel's Data Direct I/O Technology allows the PCIe NICs to read and write directly to the L3-cache instead of to the main memory. In extremely bandwidth constrained situations (using 4 Infiniband controllers or similar), this lowers power consumption and reduces latency by another 18%, which is a boon to HPC users with 10G Ethernet or Infiniband NICs.
The new Xeon also supports faster DDR3-1600, up to 2 DIMMs per channel that can run at 1600 MHz.
Ian’s Analysis
In my line of computational chemistry, several E5-2600 characteristics would be very important to throughput:
- The improved core and µop cache should boost IPC through the roof with calculations that can take advantage, especially advanced trigonometric functions.
- The increase in L3 cache would reduce stress on jumps out to main memory for values, although the improved memory bandwidth would also help in this regard.
- More cores are always welcome – Turbo 2.0 would help with pre-release code testing, which often occurs in debug / single thread mode.
- An increase of memory limits would help various simulation scenarios, as well as aid having VMs of different environments.
- The move up to PCIe 3.0 helps any GPGPU simulation that requires lots of memory transfers back and forth across the bus (matrix solving), as long as the GPU supports PCIe 3.0 (K10, K20X, FirePro, not Xeon Phi which uses PCIe 2.0).
We all know the E5-2600 series is faster (one reader in response to the previous review had seen slowdown in parts of his code on E5-2600), but the question is always around “how much?”.
On paper, Johan’s article showed us the specifications side by side (along with Opteron counterparts):
|
Xeon E5-2600 Sandy Bridge-EP |
Opteron 6200 Interlagos |
Opteron 6100 Magny-Cours |
Xeon 5600 Westmere |
|
|
Cores/Threads Modules/Threads |
8/16 | 12/12 | 6/12 | |
| 8/16 | ||||
| L1 Instruction |
8x 32KB 4-way |
8x 64KB 2-way |
12x 64KB 2-way |
6x 32KB 4-way |
| L1 Data |
8x 32KB 8-way |
16x 16KB 4-way |
12x 64KB 2-way |
6x 32KB 8-way |
| L2 Cache | 8x 256 KB | 4x 2MB | 12x 512KB | 6x 256KB |
| L3 Cache | 20 MB | 2x 8MB | 2x 6MB | 12 MB |
|
Mem Bandwidth (Per Socket) |
51.2 GB/s | 51.2 GB/s | 42.6 GB/s | 32 GB/s |
| IMC Clock Speed | On Die | 2 GHz | 1.8 GHz | 2 GHz |
| Interconnect |
2x QPI 2.0 8 GT/s |
4x HT 3.1 6.4 GT/s |
4x HT 3.1 6.4 GT/s |
2x QPI 4.8-6.4 GT/s |
| Transistors | 2.26 B | 2x 1.2 B | 2x 0.9 B | 1.17 B |
| Die Size mm2 | 416 | 2x 315 | 2x 346 | 248 |
As well as the subsequent pricing difference:
| Intel vs. Intel 2-socket SKU Comparison | |||||||||
|
Xeon 5600 |
Cores/ Threads |
TDP |
Clock (GHz) |
Price |
Xeon E-5 |
Cores/ Threads |
TDP |
Clock (GHz) |
Price |
| High Performance | High Performance | ||||||||
| 2690 | 8/16 | 135W | 2.9/3.3/3.8 | $2057 | |||||
| X5690 | 6/12 | 130W | 3.46/3.6/3.73 | $1663 | 2680 | 8/16 | 130W | 2.7/3.1/3.5 | $1723 |
| 2670 | 8/16 | 115W | 2.6/3/3.3 | $1552 | |||||
| 2665 | 8/16 | 115W | 2.4/2.8/3.1 | $1440 | |||||
| X5675 | 6/12 | 95W | 3.06/3.33/3.46 | $1440 | |||||
| X5660 | 6/12 | 95W | 2.8/3.06/3.2 | $1219 | 2660 | 8/16 | 95W | 2.2/2.6/3.0 | $1329 |
| X5650 | 6/12 | 95W | 2.66/2.93/3.06 | $996 | 2650 | 8/16 | 95W | 2/2.4/2.8 | $1107 |
| Midrange | Midrange | ||||||||
| E5649 | 6/12 | 80W | 2.53/2.66/2.8 | $774 | 2640 | 6/12 | 95W | 2.5/2.5/3 | $885 |
| 2630 | 6/12 | 95W | 2.3/2.3/2.8 | $612 | |||||
| E5645 | 6/12 | 80W | 2.4/2.53/2.66 | $551 | |||||
| 2620 | 6/12 | 95W | 2/2/2.5 | $406 | |||||
| E5620 | 4/8 | 80W | 2.4/2.53/2.66 | $387 | |||||
| High clock / budget | High clock / budget | ||||||||
| X5647 | 4/8 | 130W | 2.93/3.06/3.2 | $774 | 2643 | 4/8 | 130W | 3.3/3.3/3.5 | $885 |
| E5630 | 4/8 | 80W | 2.53/2.66/2.8 | $551 | |||||
| E5607 | 4/4 | 80W | 2.26 | $276 | 2609 | 4/4 | 80W | 2.4 | $294 |
| Power Optimized | Power Optimized | ||||||||
| L5640 | 6/12 | 60W | 2.26/2.4/2.66 | $996 | 2650L | 8/16 | 70W | 1.8/2/2.3 | $1107 |
| 5630 | 4/8 | 40W | 2.13/2.26/2.4 | $551 | 2630L | 8/16 | 60W | 2/2/2.5 | $662 |
In my experience, workstations for research are often prebuilt, so if the system builder makes a 10% markup, this would extrapolate the prices even more. For the processors we are focusing on today, the boxed version of the X5690 sits at $1666 each and the E5-2690 is $2061 – about a 25% price difference moving up to the E5-2690. However as a system the price difference may be slightly more, when we include memory and power supplies into the mix – even more if you want to expand the functionality for new interfaces. When dealing with a personal machine, a user can often recoup the cost by selling on the old hardware, making the cost more palatable – the research group cannot do the same, and more often than not the old hardware gets passed down to experimentalists, or sits in the corner when extra CPU power is needed. That makes the price an absolute cost, rather than an upgrade difference.
Whenever I get told that a component is too expensive (a lot of users are currently berating the price of NVIDIA’s GTX Titan, for example), my response is often this:
- Look at what you are currently using, and the performance increase that the better part would give
- If time is money, calculate how much time you would save using the newer component. Convert that into a cost benefit analysis (i.e. completing a contract in 6 months rather than 7 months) as more computation can be processed.
- If the cost can be recouped over 12 months, the purchase is probably justified (depending on who finances what) and will allow you to consider another upgrade in 12 months.
It is quite rare to be in a situation where the computational time is the limiting factor in a project, although I do acknowledge that when dealing with long simulations or calculations it can be. But if you can finish analyzing results in 4 hours rather than 6, if there is an error, it can be fixed and re-run in a shorter time. Essentially the more you require computational throughput for a project, the better the cost analysis usually is.
With all this said, the proof is always going to be in the numbers – I would suggest that for each situation our readers face, to weigh up the computational aspects of their work. In research, I spent more time organizing mathematics and coding than simulating, though when simulating some of them would take a week on a GTX 480 GPU, and I would run several batches at once. If Titan was around then and could save 40% of that time, I would have plugged my research supervisor for one in an instant. Similar arguments would have been made on the non-GPU side of the research, as often we would use each other’s 16 thread machines to get stuff done (and then repeat it if there was a coding error).








44 Comments
View All Comments
alpha754293 - Tuesday, March 5, 2013 - link
Sorry, I'm back. Where was I? oh yes...Unless that you were purely running single-threaded, single process jobs (or maybe even lightly multithreaded, single process jobs) - I would think that to say that it is favouring a single-CPU system might be a little bit misleading.
Even with single-socket systems, if it's got multiple cores, then you can parallelize amongst those as well.
Some commercial programs too favour 2^n cores as well, which would make quite a difference between having 8- or 16-cores vs. 6 or 12 (because some programs won't even run properly if it isn't 2^n).
Also it was interesting to see that you didn't run the implicit 3D grid solver benchmark.
Actually, MPI might not has as much to do with memory than you might think. Considering that the world's top supercomputers haven't maxed out the memory capacity per socket, I doubt that. It IS, however, much better at the actual parallelization of the task than OpenMP.
"‘Is moving from Westmere-EP to Sandy Bridge-EP a reasonable upgrade’, in the majority of our scenarios it probably is not"
It really depends. If you're writing your own code (which is what you're doing), and you have a lot of control over it, then that MIGHT be a true statement. (And it also depends on the state of your code too. If you're almost always in a permanent alpha phase (because you keep adding new capability and modules to it), then chances are, you might not even get around to parallelizing it (because you want to make sure that the base solver is robust first before you add the additional complexity of parallelization on top of that).
But if, say, suppose that you're doing research on crash and crash safety; and you're using a commercial code - some of those would just favour more cores period (see Johan's latest benchmark on the Opteron for details).
And as to whether or not you can run it on a GPU; the problem with that is that you have to make sure that every system in your working/research group has the same capable GPU hardware; otherwise, those that don't can't even run it, and those that have lesser-capable GPUs - might not get the benefits of using a GPU as much as you think, if at all.
(My GTX 660 OC's double precision performance is actually slightly SLOWER than the double precision performance of my 3930K OC'd to 4.5 GHz.)
alpha754293 - Tuesday, March 5, 2013 - link
Also, as far as I know/can remember - not everything can make use of AVX - both in terms of programs and also in terms of fundamental math operations.And I would suspect that you might also have slight performance variations if you were to recompile on the Sandy Bridge vs. on the Westmere-EP platforms (rather than sharing the binaries between the two - unless you purposely don't make it target specific).
wingless - Monday, March 4, 2013 - link
Somebody on my folding team is building this setup with dual Titans as a folding/gaming rig. The ultimate in computation, gaming, and space heating!yougotkicked - Monday, March 4, 2013 - link
I just wanted to say I found this analysis rather interesting. I'm a undergrad CS major, but I work in the IT office for the chemical engineering and material science dept. at a research university, so this breakdown of the relationship between simulations and hardware was really fascinating for me.Just to give some perspective on the pricing of an OEM-built system using E5-26XX parts, one of the research groups I work with recently bought a dual E5-2687W system from HP with 128 gigs of ram, liquid cooling, and a mid-range workstation GPU; The whole system came in at over $10,000. admittedly this includes a ~$1000 monitor and 4 hard drives, but this is probably at least a 30% margin over the cost of hardware, so the 10% margin used in the article may be on the conservative side.
P.S. we didn't suggest that system to the researchers, they bought it on their own.
colonelpepper - Monday, March 4, 2013 - link
HP & Dell systems are much more expensive than the same system built by a "system integrator" <-- I believe that's what they're calledI've read in other forums that system integrators building you a custom system add about 10% to the price tag.
yougotkicked - Monday, March 4, 2013 - link
That sounds reasonable, my only gripe would be that many researchers would not seek out a system integrator and just turn to a big name like HP. Had they sought the advice of the IT office I would have suggested we build it in-house for no markup at all.Kevin G - Monday, March 4, 2013 - link
Dell and HP's workstation lines carry a much higher premium than what you'd get DIY. The difference is in their warranties. Since dual socket workstations are effectively using low end servers in a tower chassis and they'll offer warranties very similar to what you can get for a 24/7/365 running server. While I'm not a big fan of Dell's hardware, I will say that they do follow through on their warranties. I've seen them get a replacement hard drive to my facility in under 4 hours as that is the level of support I was paying for. It wasn't cheap but it was worth it considering the business need.With the scientific slant, such warranties may turn out to be overkill as is going with OEM's. You'd still want to have the necessary data protections in place like ECC memory, redundant storage and a good backup policy while the simulation is running. However, what is the worst case that could happen when something does go wrong with the basic protections in place? Generally it is simply running the simulation again. Time is money and there are often some deadlines to meet. So if the simulation can't realistically be run again or it'd cost to much to run again, then going with an OEM that'll help achieve greater uptime is worth it.
As for the price of some of these components individually, I'm about to drop ~$1000 USD on a 128 GB memory upgrade. OEM's like Dell and HP get such parts far cheaper than DIY users due to bulk purchasing power. It is far higher than 10% margin for them in terms of raw hardware costs.
IanCutress - Tuesday, March 5, 2013 - link
The dual E5520 systems from Dell (with 4GB RAM because research department limited us to XP 32-bit) I used for research, with basic storage and a monitor each, ran up to £2k per order back in 2009. After a month of waiting to be delivered (after tons of initial hassle with the department IT guy), it turns out the systems arrived shortly after ordering and our IT guy had decided to hide them in a different building on campus and 'forgot to tell us'. The monitors were in a building the other side of campus. Fun fun fun! Needless to say, we were all rather annoyed. But looking back, I should have just asked for a single powerful Xeon workstation.yougotkicked - Tuesday, March 5, 2013 - link
Yikes, sounds like your IT guy needs to get his act together. We'd never get away with that kind of stuff here.My university has a few super-computing clusters available for researchers running truly large simulations, but because of that many groups choose not to buy systems powerful enough to run their mid-sized simulations and the clusters are usually booked a while in advance. The HP system was purchased primarily because the group was sick of waiting for their simulations to get a turn on the supercomputers.
If only there were a folding@home style client that researchers could easily program for, we could turn our computer labs into compute clusters at night.
colonelpepper - Monday, March 4, 2013 - link
This would be a very poor time to spend thousands of dollars on a high-end 2600 CPUs!The Xeon 2600 series is getting a refresh soon, better to wait and get more CPU for your buck... unless you're dying to spend big $$ now that is:
http://2.bp.blogspot.com/-zhrS1C8wbk0/UHj_HxsrMTI/...
that link is to the largest image I could find of Intel's Xeon Roadmap that was leaked late last year