Analyzing Intel’s Discrete Xe-HPC Graphics Disclosure: Ponte Vecchio, Rambo Cache, and Gelato
by Dr. Ian Cutress on December 24, 2019 9:30 AM ESTXe: Flavors and Architecture
Unlike Baskin Robbins, only 3 Flavors
Prior to the disclosures made at HPC DevCon, Intel had previously stated that its Xe design, the Xe architecture, would stretch from integrated graphics all the way through to mid-range graphics, enterprise graphics, and then into the datacentre for use in AI, acceleration, virtualized graphics, and everything else. At the entry level, users should expect ‘TeraFLOPs’ of performance, while at the datacenter level there will be ‘PetaFLOPs’ of performance. The graph looked something like this:
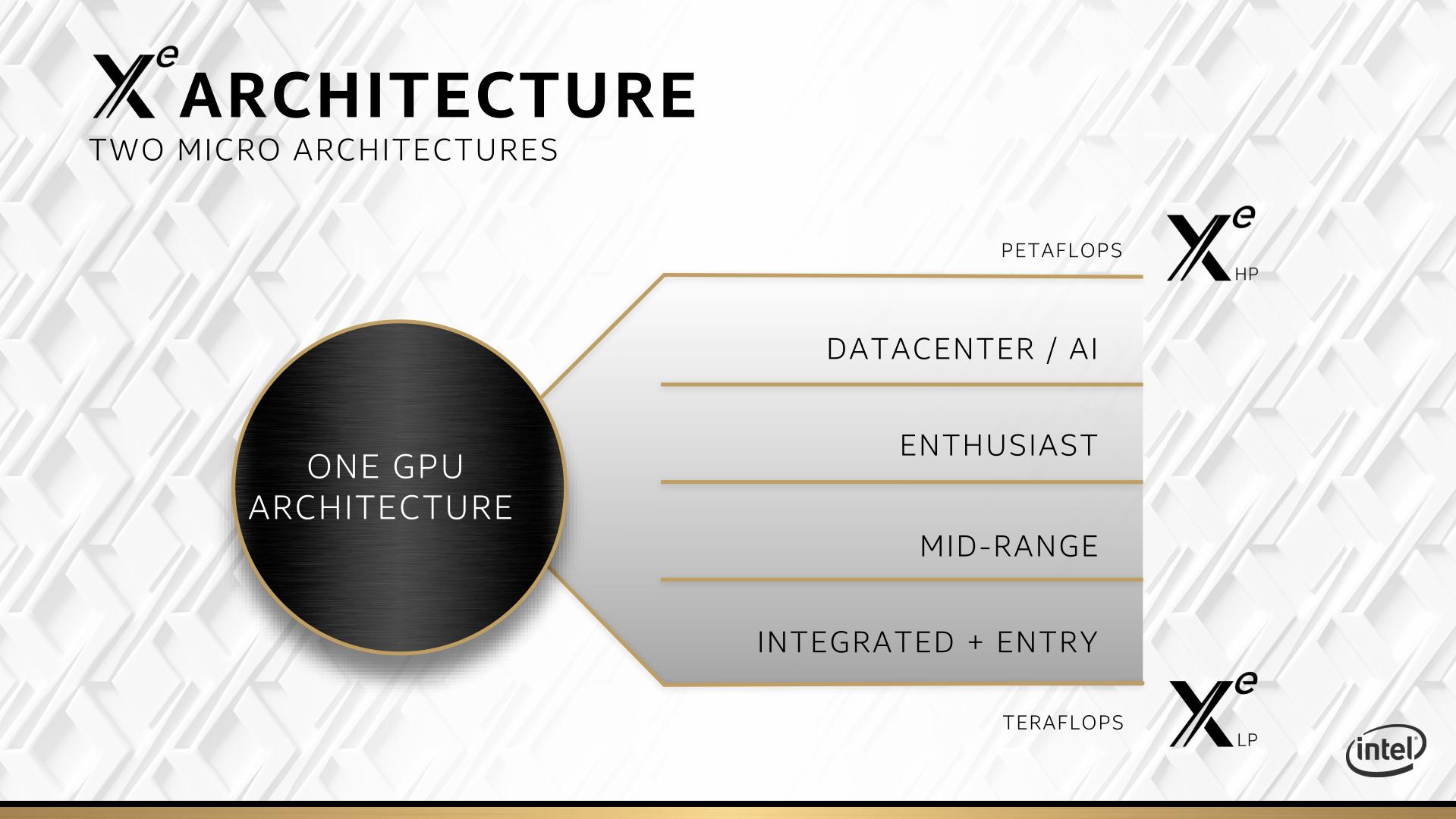
At the time Intel specified that there would be two versions of Xe across this whole range. One of the big reveals of Intel’s announcements was not only the emergence of a third variant of Xe, but also the naming of all three variants.
At the entry level will be Xe-LP, or Low Power. This will cover all of the integrated graphics solutions – Raja Koduri said that that the design of LP would push up to 20 W of graphics power. He also stated that the LP design is scalable, up to 50 W, but there are no plans to launch LP at that power as it becomes less power efficient. By this, we should expect to see LP in traditional mobile form factors up to 45 W, and probably in monolithic desktop CPUs. From this, we should surmise that LP is strictly for mobile and integrated graphics solutions, and unlikely to be available in a discrete form. By discrete, I mean a PCIe card form factor – if Intel were to make discrete LP silicon as products, it might be available to extend what is already available in notebook form factor processors.
For the mid-range, enthusiast, and datacenter, we have Xe-HP, or High Power. This is where Intel’s discrete form factor graphics is going to play, likely everything from 50 W up to 250 W or higher. Given the importance of the discrete graphics card space, Intel is going to have to attack with Xe-HP with both hardware and software support, including day-0 drivers. Intel didn’t go into any detail regarding Xe-HP, which we expect to be presented sometime in 2020.
The new third arm will be Xe-HPC, or High Performance Computing. Where the LP and HP variants will have an angle of graphics output to them, HPC is all about improving raw throughput.

The new Ponte Vecchio GPU, which we’ll talk about in the following pages, falls under this Xe-HPC microarchitecture. Intel was clear to point out that Xe-HPC isn’t so much ‘a new high level’ version of Xe, but moreso that it will cover the compute heavy workloads compared to the graphics heavy workloads. A great diagram they put out was this:
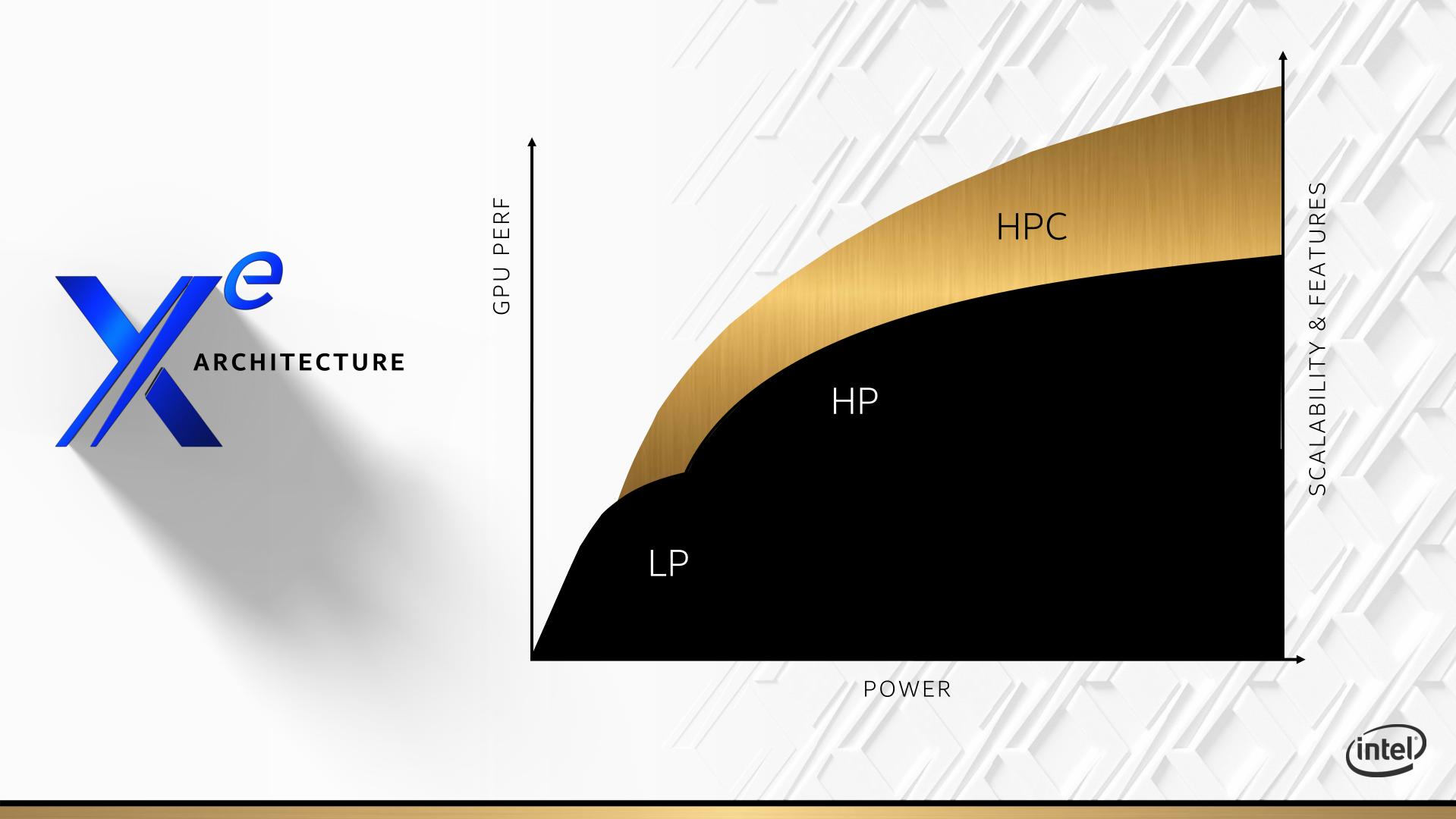
This shows LP taking the low end market, HP going for a higher performance overtone, and then HPC will scale all the way from the top of LP, through all of HP, and beyond HP. Because the supercomputer deployments that use this hardware can better accommodate higher power consumption hardware than normal high-end PCs or even servers, the HPC variants are likely to go up to 400W or even more (we saw a PCIe card with a 500W TDP this year at Supercomputing, so that might be a new norm).
Structurally Sound: Architecture
Every GPU design is fundamentally built upon its vector width capability. A GPU is a big fancy vector machine, and so a balance has to be made between super wide vectors that can accommodate lots of calculations against lots of tiny vector machines that can do things in parallel. One of the biggest drivers for vector width comes back to graphics calculations: being able to manipulate a certain number of pixels within a vector with at the right time, and dealing with data coming from different places in memory, or perhaps even dealing with different kernels working on different sets of data.
Vector width also defines a lot of the software and a lot of optimizations. When speaking to Raja Koduri as part of the disclosures, he stated that trying to translate code built for a large vector width down to a smaller vector width was actually quite difficult. To that end, Xe is built with a variable vector width.

Xe contains two fundamental units: SIMT and SIMD. In essence, SIMD (single instruction, multiple data) is CPU like and can be performed on single elements with multiple data sources, while SIMT (single instruction, multiple threads) involves using the same instructions on blocks of data, as part of the whole ‘vector’ processing thing. An Xe design can be built with a number of SIMT and SIMD modules in the correct order to deal with the precise nature of the workload for that market segment. Welcome to GPU building, Lego style.
Along with SIMT and SIMD, Intel stated that both parts can work together for ‘maximum performance’ mode. This almost sounds like stretching a potential SIMT command over the SIMD units, if that is even possible. But Intel stated that the design of each unit is meant to be scalable (because of exascale). In this instance, Intel was quite keen to promote that its Xe architecture, with SIMT and SIMD units in its Xe-HPC designs at least, can scale to 1000s of units.

In that diagram it shows an 8x8 grid, with dots spreading to a 14x11 grid, but I don’t think there’s anything we can infer from this diagram.
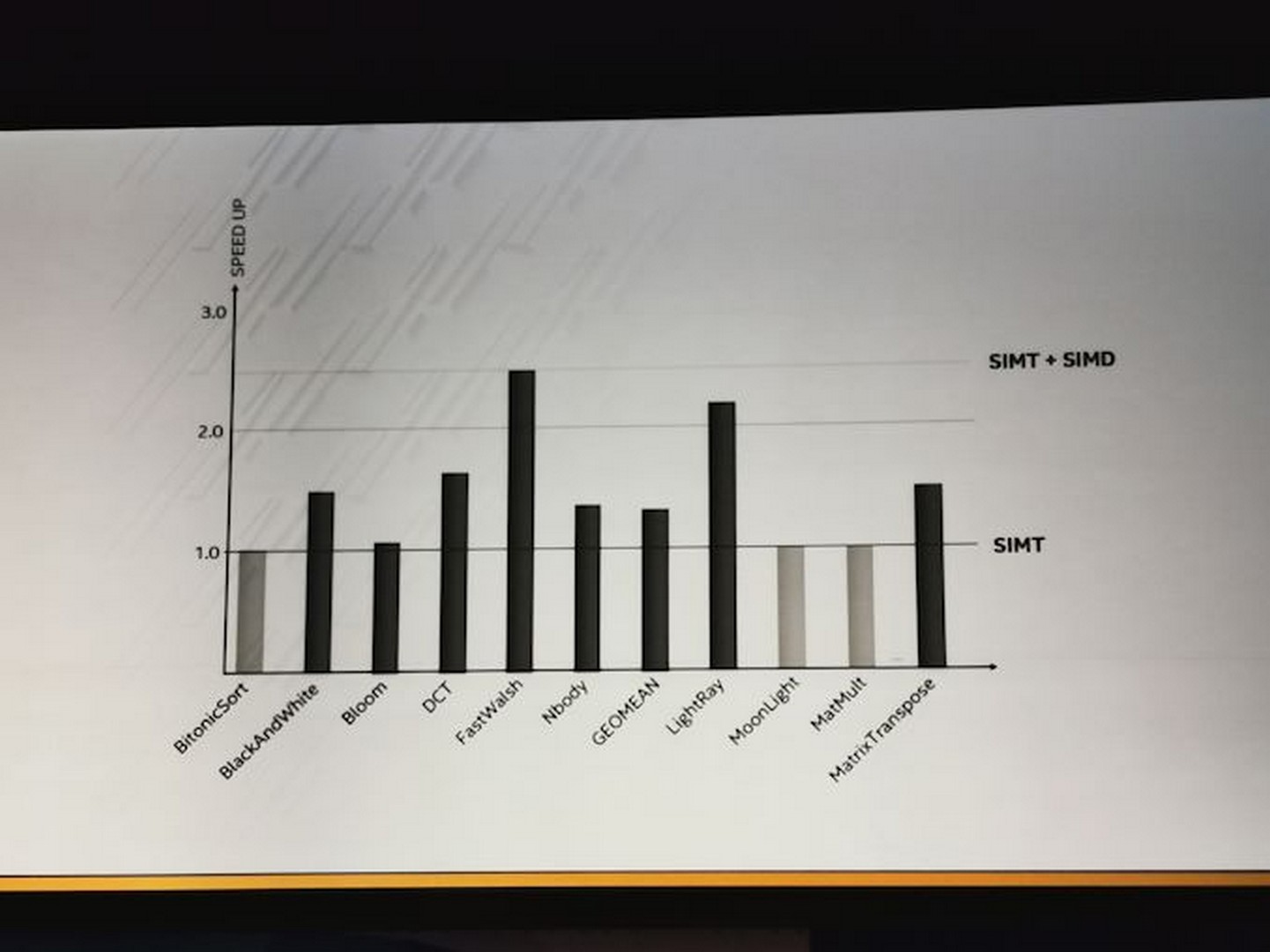
Based on Intel’s in-house simulations, they showed some areas where the combined SIMD+SIMT would help. In this instance, some of the standard SIMT codes don’t experience any speed-up and can only use SIMT units: a bitonic sort, the MoonLight ray tracer, and Matrix Multiply (that’s a big one). Other codes can experience speed-up with SIMT+SIMD combined, such as Matrix Transposing, N-body simulations, the LightRay ray tracing engine, and the biggest uplift is in FastWalsh.
What this graph suggests is that for code that is fully optimized for SIMT, then no extra SIMD is needed and they will remain idle. For code that relies on some serial work, such as N-body, or for ray tracers that are programmed differently, then when a kernel needs to perform some serial work it can move those threads to SIMD/CPU part of the hardware and proceed that way rather than having to go back to the CPU. This can be important for a lot of code speedups, but for those that are already heavily optimized for vector compute, then the presence of the SIMD units just mean wasted silicon space – keep note of that.
Execution Unit Design: A High Level
Intel was kind enough to showcase what goes into one of these Xe units, but only in the sense of a block diagram with not a lot of information.

I should state that this slide is an Xe-HPC unit, which means that other LP/HP units might look similar but have different weighting of features. It doesn’t state if this is a SIMT or SIMD unit, but this is likely a SIMT unit given what we can deduce.
If this diagram looks relatively familiar, then I share those thoughts. It looks to be an upgraded diagram of one of the execution units from Intel’s Gen graphics architecture. For a quick re-cap, that architecture was based on a 7-way pipeline with 7 threads per EU. In this instance, it is very easy to see that an Xe-HPC unit has an 8-way outline, which likely indicates 8 threads in parallel if the diagram is an accurate representation.
There’s no way to tell what sort of operations each thread can do, but the blocks on the left are likely to be for different thread functions, such as a pair of special function units at the top, while the two groups of four might be for AES instructions, or memory load/store ports, or local caches.
All we really know for sure is that Intel is putting a lot of effort in this Xe-HPC unit to support double precision. This is important, and to explain why we need to cover some truths about the high-performance computing landscape.
At the advent of GPU programming, with the wonderful delights of the early versions of CUDA, the focus was on single precision throughput: known as 32-bit floating point, or FP32. For anyone doing scientific simulations, depending on the type of work you were doing, this was either great and super-fast, or it very quickly reached a point where single precision was not enough.
I was lucky enough during my PhD to cover topics that landed on both sides of the fence, but what annoyed me was when FP32 wasn’t enough: my simulations were producing results as expected, and then suddenly flat-lined when the changes that were meant to be happening in the simulation happened to such a fine degree that FP32 didn’t have enough significant figures to compensate.
As a result, I had to switch most of my compute and data types to double precision, or FP64. This gave me another dozen or so significant figures per value, but it also put all sorts of stresses on my workloads in terms of register pressure, cache pressure, and the design had to be changed in parts to accommodate. In order to get to the same point in the simulation with FP32 and FP64 meant FP64 took longer, but I could go further and actually have meaningful results.
Thankfully at that time, NVIDIA was fairly reasonable with FP32/FP64 balancing. If it wasn’t a strict 1:1 then at least a 1/2 rate or 1/3 rate was quite sufficient, especially when it was needed. When the 1/32 rate hardware came along, we all thought it was a ploy to encourage low cost academic simulator students onto the high cost stuff, not that it was because the cards dedicated more silicon to graphics-heavy workloads.
For a long time, FP64 compute has reigned supreme. Then this thing called AI came along, with its high compute requirements for training. AI compute requirements are certainly driving the industry forward, however there seems to be arguments about performance and throughput: depending on which researcher you talk to, each might have a different preference to how precise the numbers need to be. There is a trade-off between training accuracy, training time, and compute throughput when we discuss low precision numbers (INT8, FP16) with high-precision numbers (FP32, FP64). Between training and inference (Facebook needs a lot of inference, for example) there has been a big push towards low precision compute.
So here we have two sides of the coin: FP64 for the simulators, those that deal with oil/gas, astronomy, geology, weather dynamics, and some financial analysis, while AI training works mostly in FP16/BF16 and AI inference likes INT8/FP16.
Intel’s play here with Xe-HPC is for the FP64 crowd. The promise with Xe-HPC is a 40x increase in FP64 compute performance. That being said, they didn’t say compared to what – to an old Gen design?
At this point, this is all we know about how Xe Execution Units might look, and most of the detail here applies to Xe-HPC only. What functions / balancing will go for LP or HP is unknown at this point, but I’d hazard a guess and say that those designs are built more like shader cores for graphics purposes.
XeMF: The Scalable Memory Fabric, with RAMBO CACHE
While Intel was keen to point out that the Xe-HPC execution units can scale to 1000s of units, scaling means nothing without the right way to move data in and out of those compute engines. To that end, Intel disclosed that it has developed a memory fabric for its Xe-HPC designs called XeMF.

The scalable memory fabric sits between the compute units and any attached memory – in this diagram in this instance we see HBM listed. Assuming this diagram is accurate, there are few takeaways we can get from this.
Firstly, the XeMF has three connections to each Xe-HPC compute unit (XeCU), while it only has one connection to each HBM channel. That’s a 3:1 factor in bandwidth, which might be a limitation of off-silicon data transfer.
Also, each XeCU seems to have direct connections with each other without needing to use the fabric. Again, it shows 3 connections between each XeCU, and it shows that an XeCU can only communicate with its two nearest neighbors. The diagram is showing the XeCUs in a linear fashion, which might just be for the simplicity of the diagram.
The diagram also shows each HBM channel able to speak to the next door HBM channels without going through the fabric. If that’s true, that’s new.
Then there are the connections at the top of the bottom of the fabric, likely extending the fabric to more chips. We’ll see about that in a second.

Even though I missed the picture, the next slide in this deck shows that the XeMF has a secret surprise: a special cache. In this instance it has been dubbed a ‘RAMBO’ cache, although after speaking with Raja, this won’t be the actual marketing name for this feature. What the RAMBO cache does is offer a large amount of cache for the XeCUs to call upon and store data for future use. Given that the lines on the diagram show that the cache to CU bandwidth has a 3:1 improvement over cache to HBM, then storing data for future compute is likely what this is for, as it can supply it to the CUs at a much higher bandwidth. The slide implies that the RAMBO cache is inside the XeMF chips, but in another side it says that Foveros is used in the RAMBO cache, so it might actually be distributed through the whole GPU design.
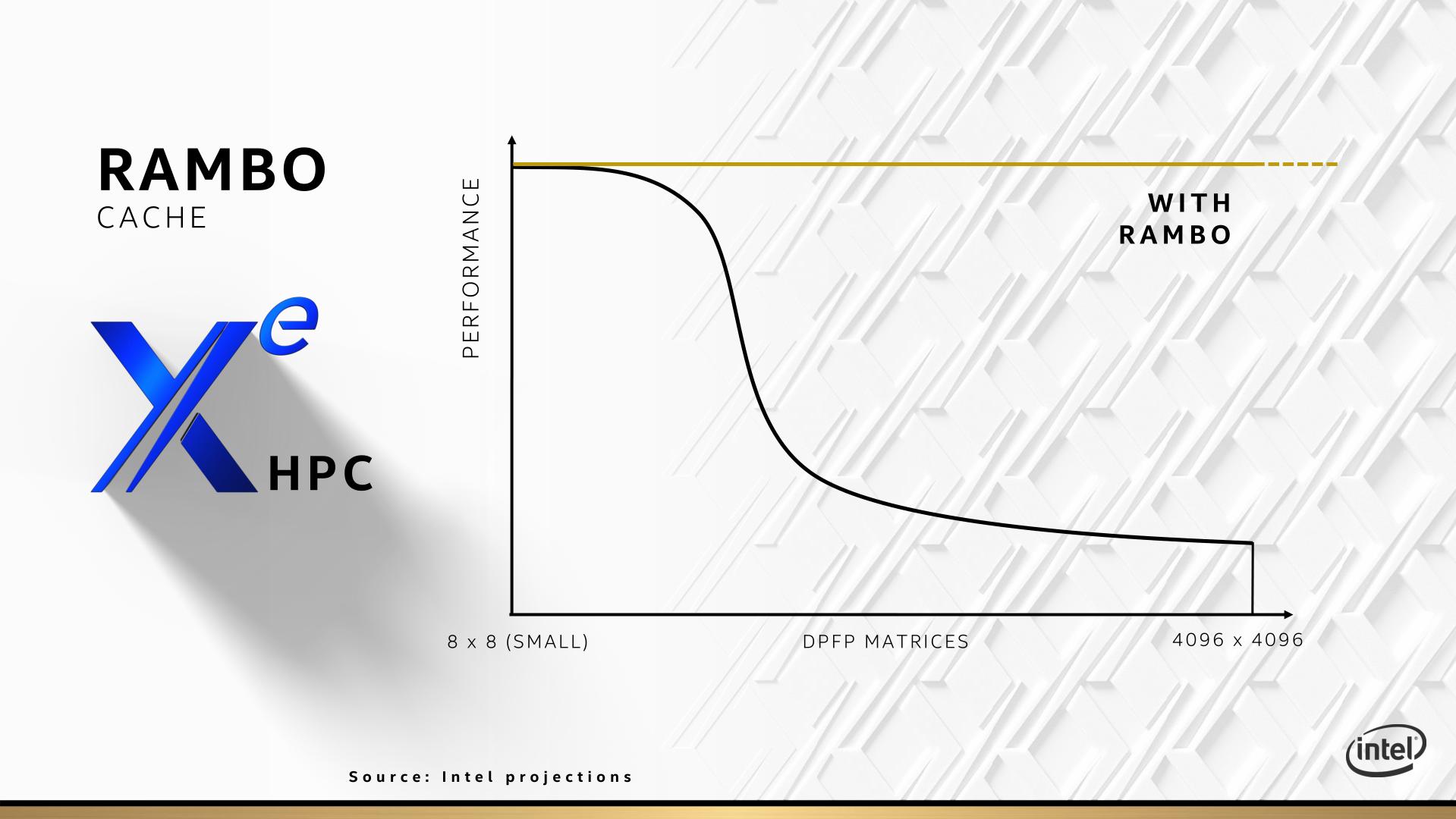
In the next slide, this is exactly what Intel tells us. Here Intel is giving the example of FP64 matrices, but doesn’t specify if this means compute or streaming bandwidth. In this instance without the RAMBO cache, the XeCU would be at peak performance with an 8x8 matrix, probably start declining somewhere around the 64x64 or 256x256 matrix, down to a low point at a 4096x4096 matrix. With the RAMBO cache, according to Intel, the ‘performance’ (again, not sure if compute or streaming), will be the same on 4096x4096 matrices as 8x8 matrices. For a lot of simulation work, that’s going to be a great addition.
A final word about the fabric: there’s no telling if XeMF will come to LP or HP designs – Intel only spoke about XeMF in the context of HPC.








47 Comments
View All Comments
FireSnake - Tuesday, December 24, 2019 - link
Having 3rd player will sure be interesting...coburn_c - Tuesday, December 24, 2019 - link
Intel sees a future where everything will be connected and capturing data, and they are gonna build the tools to data mine every bit of it and sell it to the highest bidder. Goodbye freedom, hello profit.surt - Tuesday, December 24, 2019 - link
Just wait a little bit. Very soon there will be some non-tragically-dumb police officer investigating a child death who will realize an Alexa device captured the event. There will be calls for secure storage and Megan's law reporting. It will clear up all the data listening problems very quickly.29a - Friday, December 27, 2019 - link
This.Alexvrb - Tuesday, December 24, 2019 - link
Well they're late to the party, Alphabet Inc. already does that.PeachNCream - Tuesday, December 24, 2019 - link
I see you are unfamiliar with Google, Facebook, Amazon, or Microsoft (and a bunch of smaller fish that fly well below the radar, but are actively getting to know you very well).imaheadcase - Tuesday, December 24, 2019 - link
So like what most companies do now?bank account? shared
medical record? shared (yep they can)
insurance? Shared (often with banks)
The amount of data points is insane that most people are having info shared and not even know it.
Pro-competition - Wednesday, December 25, 2019 - link
"Having 3rd player will sure be interesting..." What a vacuous statement. Are you a bot?Flunk - Wednesday, December 25, 2019 - link
Yes, I think he might be the type of bot that randomly quotes the OP and then adds "What a vacuous statement. Are you a bot?". I deeply regret writing that one but it's out there now.29a - Tuesday, December 24, 2019 - link
I’ll believe it when I see it.