Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute
by Andrei Frumusanu on March 10, 2020 8:30 AM EST- Posted in
- Servers
- CPUs
- Cloud Computing
- Amazon
- AWS
- Neoverse N1
- Graviton2

It’s been a year and a half since Amazon released their first-generation Graviton Arm-based processor core, publicly available in AWS EC2 as the so-called 'A1' instances. While the processor didn’t impress all too much in terms of its performance, it was a signal and first step of what’s to come over the next few years.
This year, Amazon is doubling down on its silicon efforts, having announced the new Graviton2 processor last December, and planning public availability on EC2 in the next few months. The latest generation implements Arm’s new Neoverse N1 CPU microarchitecture and mesh interconnect, a combined infrastructure oriented platform that we had detailed a little over a year ago. The platform is a massive jump over previous Arm-based server attempts, and Amazon is aiming for nothing less than a leading competitive position.
Amazon’s endeavours in designing a custom SoC for its cloud services started back in 2015, when the company acquired Isarel-based Annapurna Labs. Annapurna had previously worked on networking-focused Arm SoCs, mostly used in products such as NAS devices. Under Amazon, the team had been tasked with creating a custom Arm server-grade chip, and the new Graviton2 is the first serious attempt at disrupting the space.
So, what is the Graviton2? It’s a 64-core monolithic server chip design, using Arm’s new Neoverse N1 cores (Microarchitectural derivatives of the mobile Cortex-A76 cores) as well as Arm’s CMN-600 mesh interconnect. It’s a pretty straightforward design that is essentially almost identical to Arm’s 64-core reference N1 platform that the company had presented back a year ago. Amazon did diverge a little bit, for example the Graviton2’s CPU cores are clocked in at a bit lower 2.5GHz as well as including only 32MB instead of 64MB of L3 cache into the mesh interconnect. The system is backed by 8-channel DDR-3200 memory controllers, and the SoC supports 64 PCIe4 lanes for I/O. It’s a relatively textbook design implementation of the N1 platform, manufactured on TSMC’s 7nm process node.
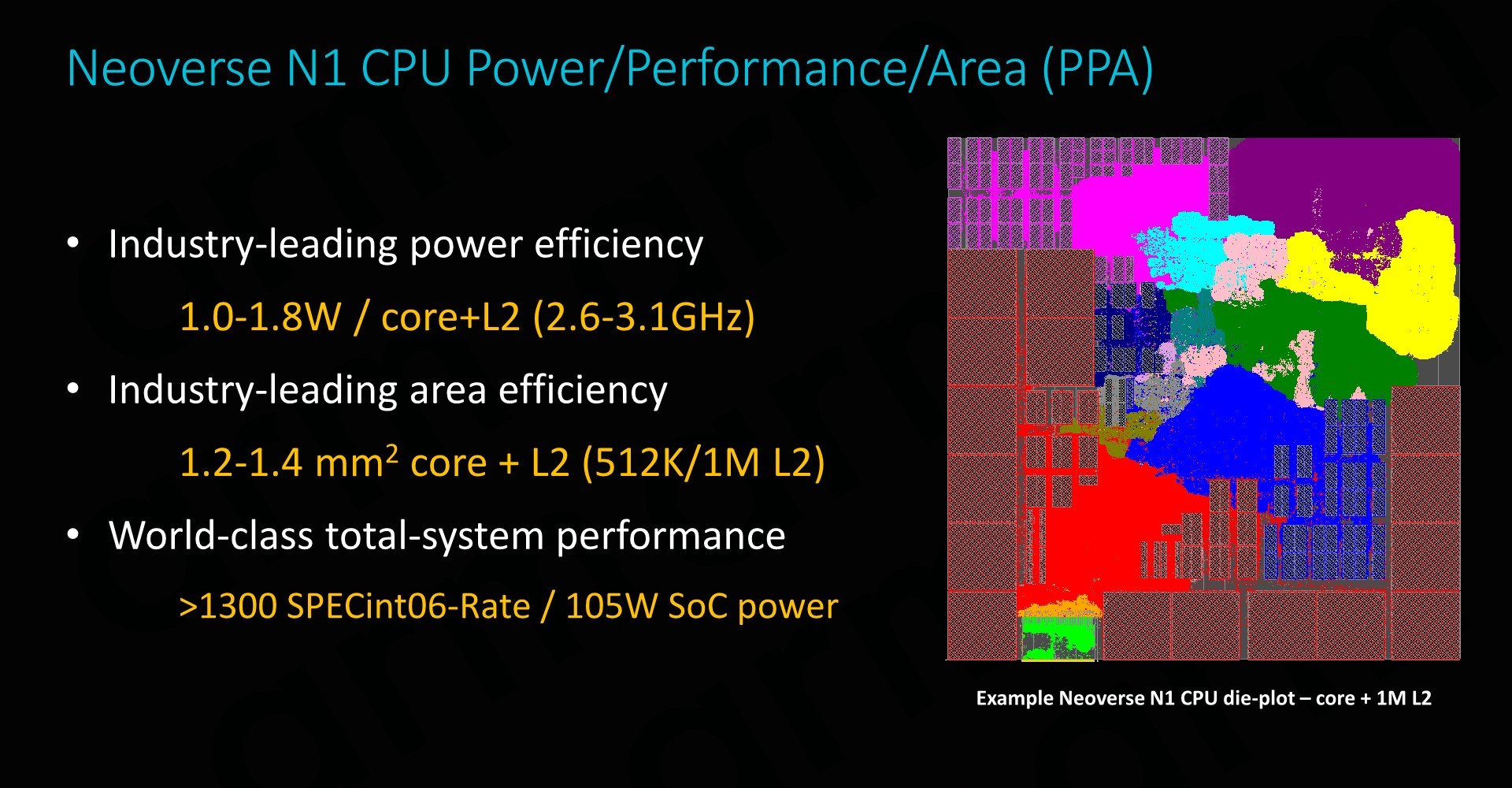
The Graviton2’s potential is of course enabled by the new N1 cores. We’ve already seen the Cortex-A76 perform fantastically in last year’s mobile SoCs, and the N1 microarchitecture is expected to bring even better performance and server-grade features, all whilst retaining the power efficiency that’s made Arm so successful in the mobile space. The N1 cores remain very lean and efficient, at a projected ~1.4mm² for a 1MB L2 cache implementation such as on the Graviton2, and sporting excellent power efficiency at around ~1W per core at the 2.5GHz frequency at which Amazon’s new chip arrives at.
Total power consumption of the SoC is something that Amazon wasn’t too willing to disclose in the context of our article – the company is still holding some aspects of the design close to its chest even though we were able to test the new chipset in the cloud. Given the chip’s more conservative clock rate, Arm’s projected figure of around 105W for a 64-core 2.6GHz implementation, and Ampere’s recent disclosure of their 80-core 3GHz N1 server chip coming in at 210W, we estimate that the Graviton2 must come in around anywhere between 80W as a low estimate to around 110W for a pessimistic projection.
Testing In The Cloud With EC2
Given that Amazon’s Graviton2 is a vertically integrated product specifically designed for Amazon’s needs, it makes sense that we test the new chipset in its intended environment (Besides the fact that it’s not available in any other way!). For the last couple of weeks, we’ve had preview access for Amazon Web Services (AWS) Elastic Compute Cloud (EC2) new Graviton2 based “m6g” instances.
For readers unfamiliar with cloud computing, essentially this means we’ve been deploying virtual machines in Amazon’s datacentres, a service for which Amazon has become famous for and which now represents a major share of the company’s revenues, powering some of the biggest internet services on the market.
An important metric determining the capabilities of such instances is their type (essentially dictating what CPU architecture and microarchitecture powers the underlying hardware) and possible subtype; in Amazon’s case this refers to variations of platforms that are designed for specialised use-cases, such as having better compute capabilities or having higher memory capacity capabilities.
For today’s testing we had access to the “m6g” instances which are designed for general purpose workloads. The “6” in the nomenclature designates Amazon’s 6th generation hardware in EC2, with the Graviton2 currently being the only platform holding this designation.
Instance Throughput Is Defined in vCPUs
Beyond the instance type, the most important other metric that defined an instance’s capabilities is its vCPU count. “Virtual CPUs” essentially means your logical CPU cores that’s available to the virtual machine. Amazon offers instances ranging from 1 vCPU to up to 128, with the most common across the most popular platforms coming in sizes of 2, 4, 8, 16, 32, 48, 64, and 96.
The Graviton2 being a single-socket 64-core platform without SMT means that the maximum available vCPU instance size is 64.
However, what this also means, is that we’re quite in a bit of an apples-and-oranges conundrum of a comparison when talking about platforms which do come with SMT. When talking about 64 vCPU instances (“16xlarge” in EC2 lingo), this means that for a Graviton2 instance we’re getting 64 physical cores, while for an AMD or Intel system, we’d be only getting 32 physical cores with SMT. I’m sure there will be readers who will be considering such a comparison “unfair”, however it’s also the positioning that Amazon is out to make in terms of delivered throughput, and most importantly, the equivalent pricing between the different instance types.
Today’s Competition
Today’s article will focus around two main competitors to the Graviton2: AMD EPYC 7571 (Zen1) powered m5a instances, and Intel Xeon Platinum 8259CL (Cascade Lake) powered m5n instances. At the moment of writing, these are the most powerful instances available from the two x86 incumbents, and should provide the most interesting comparison data.
It’s to be noted that we would have loved to be able to include AMD EPYC2 Rome based (c5a/c5ad) instances in this comparison; Amazon had announced they had been working on such deployments last November, but alas the company wasn’t willing to share with us preview access (One reason given was the Rome C-type instances weren’t a good comparison to the Graviton2’s M-type instance, although this really doesn’t make any technical sense). As these instances are getting closer to preview availability, we’ll be working on a separate article to add that important piece of the puzzle of the competitive landscape.
| Tested 16xlarge EC2 Instances | |||
| m6g | m5a | m5n | |
| CPU Platform | Graviton2 | EPYC 7571 | Xeon Platinum 8259CL |
| vCPUs | 64 | ||
| Cores Per Socket | 64 | 32 | 24 (16 instantiated) |
| SMT | - | 2-way | 2-way |
| CPU Sockets | 1 | 1 | 2 |
| Frequencies | 2.5GHz | 2.5-2.9GHz | 2.9-3.2GHz |
| Architecture | Arm v8.2 | x86-64 + AVX2 | x86-64 + AVX512 |
| µarchitecture | Neoverse N1 | Zen | Cascade Lake |
| L1I Cache | 64KB | 64KB | 32KB |
| L1D Cache | 64KB | 32KB | 32KB |
| L2 Cache | 1MB | 512KB | 1MB |
| L3 Cache | 32MB shared | 8MB shared per 4-core CCX |
35.75MB shared per socket |
| Memory Channels | 8x DDR4-3200 | 8x DDR-2666 (2x per NUMA-node) |
6x DDR4-2933 per socket |
| NUMA Nodes | 1 | 4 | 2 |
| DRAM | 256GB | ||
| TDP | Estimated 80-110W? |
180W | 210W per socket |
| Price | $2.464 / hour | $2.752 / hour | $3.808 / hour |
Comparing the Graviton2 m6g instances against the AMD m5a and Intel m5n instances, we’re seeing a few differences in the hardware capabilities that power the VMs. Again, the most notorious difference is the fact that the Graviton2 comes with physical core counts matching the deployed vCPU number, whilst the competition counts SMT logical cores as vCPUs as well.
Other aspects when talking about higher-vCPU count instances is the fact that you can receive a VM that spans across several sockets. AMD’s m5a.16xlarge here is still able to deploy the VM on a single socket thanks to the EPYC 7571’s 32 cores, however Intel’s Xeon system here employs two sockets as currently there’s no deployed Intel hardware in EC2 which can offer the required vCPU count in a single socket.
Both the EPYC 7571 and the Xeon Platinum 8259CL are parts which aren’t publicly available or even listed on either company’s SKU list, so these are custom parts for the likes of Amazon for datacentre deployments.
The AMD part is a 32-core Zen1 based single-socket solution (at least for the 16xlarge instances in our testing) clocking in at 2.5 GHz all-cores to up to 2.9GHz in lightly threaded scenarios. The peculiarity of this system is that it’s somewhat limited by AMD’s quad-chip MCM system which has four NUMA nodes (one per chip and 2-channel memory controller), a characteristic that’s been eliminated in the newer EPYC2 Zen2 based systems. We don’t have concrete confirmation on the data, but we suspect this is a 180W part based on the SKU number.
Intel’s Xeon Platinum 8259CL is based on the newer Cascade Lake generation CPU cores. This particular part is also specific to Amazon, and consists of 24 enabled cores per socket. To reach the 16xlarge 64 vCPU count, EC2 provides us a dual-socket system with 16 out of the 24 cores instantiated on each socket. Again, we have no confirmation on the matter, but these parts should be rated at 210W per socket, or 420W total. We do have to remind ourselves that we’re only ever using 66% of the system’s cores in our instance, although we do have access to the full memory bandwidth and caches of the system.
The cache configuration in particular is interesting here as things differ quite a bit between platforms. The private caches of the actual CPUs themselves are relatively self-explanatory, and the Graviton2 here does provide the highest capacity of cache out of the trio, but is otherwise equal to the Xeon platform. If we were to divide the available cache on a per-thread basis, the Graviton2 leads the set at 1.5MB, ahead of the EPYC’s 1.25MB and the Xeon’s 1.05MB. The Graviton2 and Xeon systems have the distinct advantage that their last level caches are shared across the whole socket, while AMD’s L3 is shared only amongst 4-core CCX modules.
The NUMA discrepancies between the systems aren’t that important in parallel processing workloads with actual multiple processes, but it will have an impact on multi-threaded as well as single-threaded performance, and the Graviton2’s unified memory architecture will have an important advantage in a few scenarios.
Finally, there’s quite a difference in the pricing between the instances. At $2.46 per hour, the Graviton2 system edges out the AMD system in price, and is massively cheaper than the $3.80 per hour cost of the Xeon based instance. Although when talking about pricing, we do have to remember that the actual value delivered will also wildly depend on the performance and throughput of the systems, which we’ll be covering in more detail later in the article.
We thank Amazon for providing us with preview access to the m6g Graviton2 instances. Aside from giving us access, Amazon nor any other of the mentioned companies have had influence in our testing methodology, and we paid for our EC2 instance testing time ourselves.








96 Comments
View All Comments
SarahKerrigan - Tuesday, March 10, 2020 - link
That single-thread performance is extremely impressive. The multithreaded scaling is ugly, though. Back when N1 was announced, ARM seemed to think 1MB/core was a good spot for Neoverse LLC - I wonder why both Graviton and Altra are going for considerably less.shing3232 - Tuesday, March 10, 2020 - link
it's gonna costly(die and power wise) to build a interconnect for 64C with good performance. by the time, it would lost its power/perf edge I suppose.Tabalan - Tuesday, March 10, 2020 - link
Scaling might not be optimal, but performance loses are to expected if you greatly reduce available cache. In the end, MT performance is still far ahead of competition.ballsystemlord - Thursday, March 12, 2020 - link
You have to remember that the competition is not 64 cores, but 64v cpus. The difference is 60% or more. The Arm Graviton2 is being placed into the best possible light by this comparision.ballsystemlord - Thursday, March 12, 2020 - link
I mean 60% for the cores that are actually 1 thread. As in, the performance boost by turning on SMT is 40% best case scenario.autarchprinceps - Sunday, October 25, 2020 - link
I have to disagree. You seem to forget that the arm chip is cheaper. It’s an additional win if it manages to integrate more cores and yet still achieve a comparable single threaded performance. It’s not unfair to compare two products with one seeming to have a stat advantage from the start, if it’s still cheaper or costs the same. Why should a customer care?zamroni - Thursday, March 12, 2020 - link
L caches uses sram which needs 6 transistors per bit.So, every 1MB needs all least 48 millions transistors without counting transistors for the controller
dianajmclean6 - Monday, March 23, 2020 - link
Six months ago I lost my job and after that I was fortunate enough to stumble upon a great website which literally saved me• I started working for them online and in a short time after I've started averaging 15k a month••• icash68.coMRallJ - Tuesday, March 10, 2020 - link
Comparisons made are to the whole core performance of Graviton to just thread performance of Xeon/EPYC. It's very problematic.Also TDP rating for the graviton is off by 50% based on what was reported at re:Invent.
Andrei Frumusanu - Tuesday, March 10, 2020 - link
I go over the core/SMT topic in the article, it's only a problem from a hardware comparison aspect, but it's very much the correct comparison from a cloud product offering comparison. The value proposition also does not change depending on core count, the instances are priced at similar tiers.